Dual Site
Overview
Datacenters
Presentation
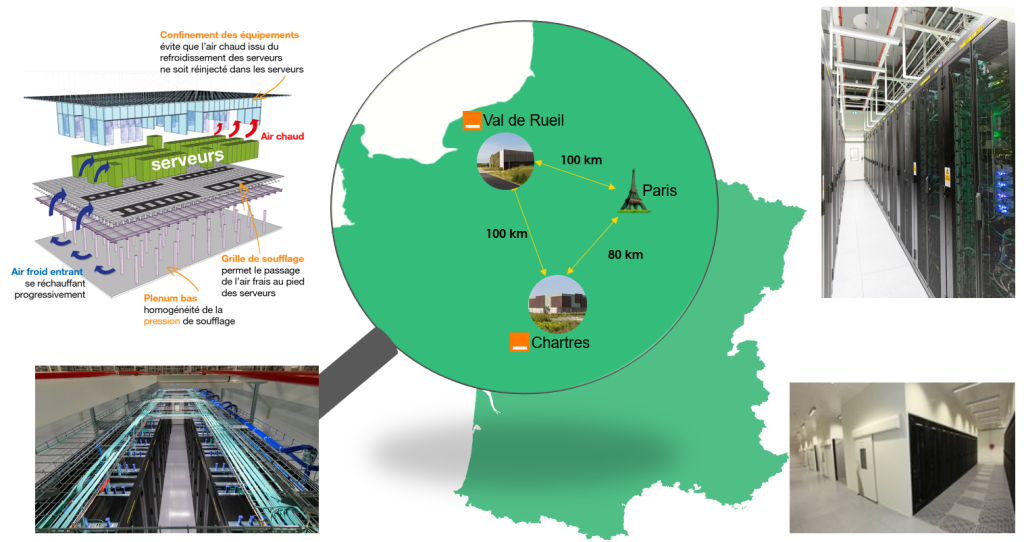
Cloud Avenue (NGP) is deployed in 2 datacenters located in France. These Orange-designed datacenters incorporate free cooling technology, enabling them to achieve a PUE of less than 1.3. A datacenter comprises several buildings, each consisting of 4 rooms that are totally independent in terms of power, network and cooling. The very design of the buildings guarantees a 4-hour fire-free period between rooms.
| Datacenter | Code | Number of rooms hosting customer workloads |
|
Val de Reuil – Normandy 1 |
VDR | 2 |
| Chartres | CHA | 1 |
The backup solution used on the platform is hosted in a separate room, independent of the rest of the platform, whatever the site.
The Val de Reuil site management infrastructure is spread over 3 rooms for maximum resilience, with .
Certifications
Our data centers are certified :
ISO 14 001 for environmental management
ISO 50 001 for energy management
ISAE 3402/ SOC2 American standard derived from SOX, certifying compliance with physical access and operating security requirements.
They are also Mastercard and PCI DSS certified for banking data security.
Interconnection
The VDR and CHA Data Centers are interconnected by a resilient L3 VXLAN infrastructure with multiple low-latency 100Gb/s links (WDM) between the sites.
Cloud Avenue has four dedicated 25Gb/s links provided by this underlying infrastructure.
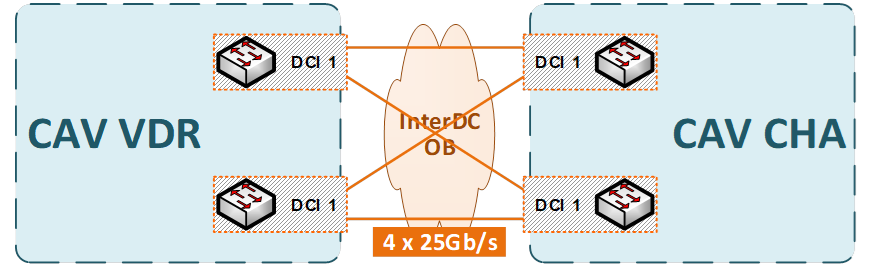
The latency between the two Cloud Avenue sites is less than 5ms.
Principle and functionalities
Each site is independent and autonomous. However, it is possible to use the resources of each site simultaneously, in order to build disaster recovery or business continuity scenarios.
Several configurations are possible, each allowing different use cases, detailed below.
Bi-site active/passive
This topology enables you to set up a disaster recovery plan (DRP), quite simply, using the tool integrated into the VCD portal, VCDA (vCloud Director Availability). The VM Replication page provides all the information you need to know about how VCDA works. Depending on the replication policy chosen, the RPO can be as long as 5 minutes.
Active/active bi-site
This topology provides several redundancy mechanisms, and in particular enables the implementation of a business continuity plan (BCP), by installing the same application on both sites.
Applications can be placed in active/active mode between Val de Reuil and Chartres, with an RPO of 0, subject to the following conditions:
- Virtual machines use an application replication mechanism (e.g. MySQL replication)
- Replication is synchronous
Another way of obtaining an RPO of 0 for “business-critical” applications is to deploy them on a vCoD infrastructure in “extended cluster” mode (see Use Case 5).
Use cases
Several use cases are supported in a dual-site configuration.
Use case 1 – DRP
An application is deployed on a nominal site, here Val de Reuil. The application is protected by VCDA and ready to restart on the backup site, in this case Chartres.
The application is exposed on the Internet and uses a public IP address, referenced in a public DNS.
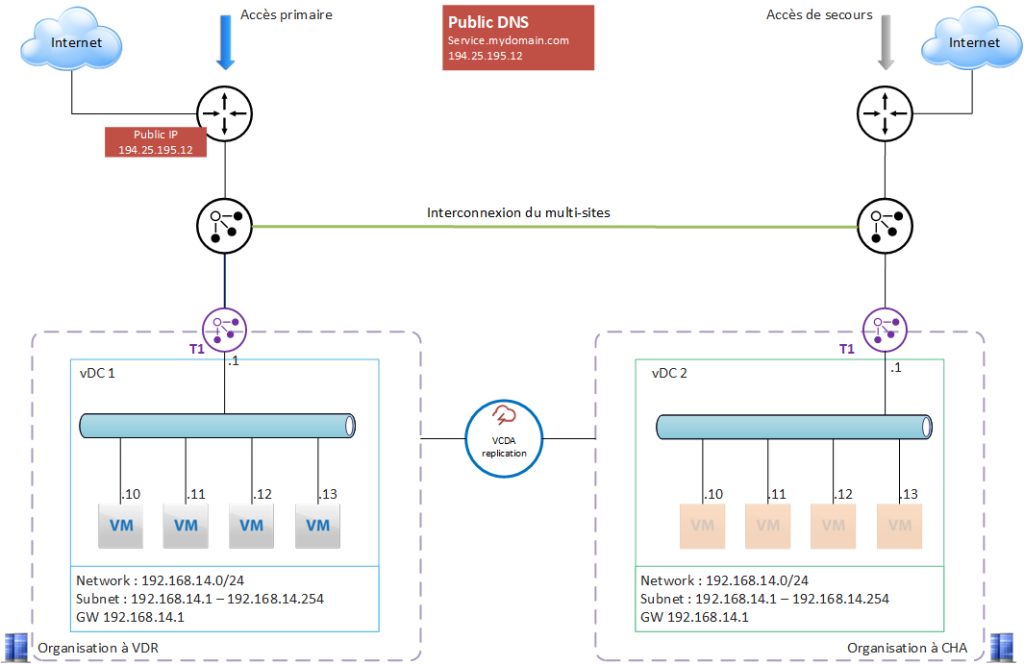
In the event of failure of one or more components of the platform, rendering the service inoperative, the customer can trigger his DRP (configured with VCDA) and restore the service in a very short time, with minimum loss of data.
In this case, the public IP will be migrated to the backup site, enabling the service to be fully available once the BGP sync has been completed.
Once service has been re-established on Val de Reuil, it’s natural to go back to VCDA, with no loss of data. The public IP will then migrate to the nominal site.
Important: choose vDCs in PAYG mode on the recovery site, to minimize billing on the backup site.
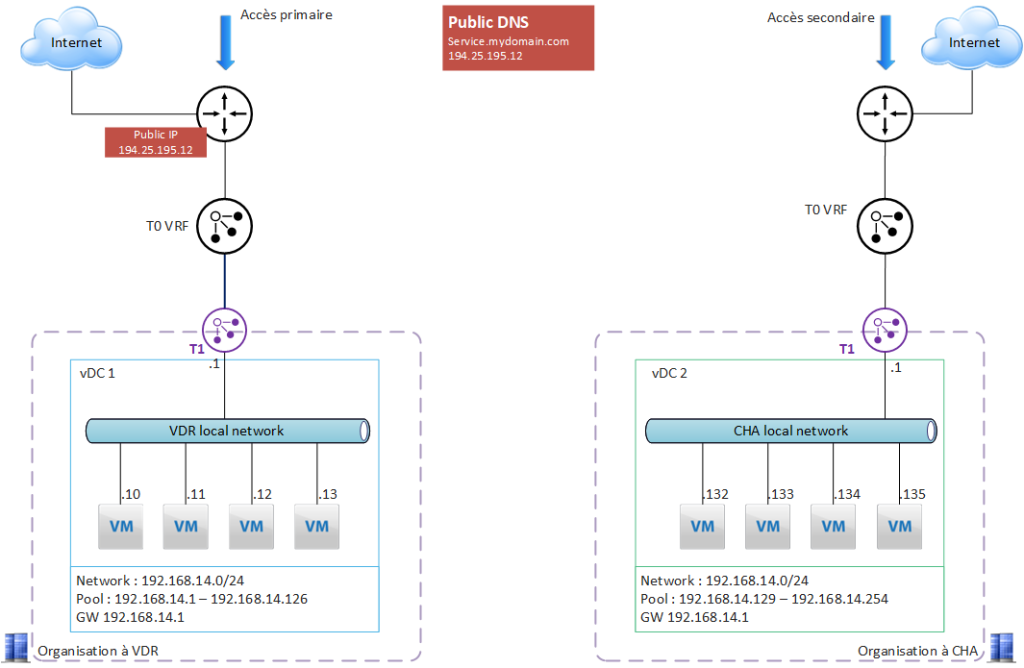
Use case 2 – Internet access redundancy
The 2 organizations on Val de Reuil and Chartres are initially independent.
Requirements :
- communicate VMs on the 2 sites
- protect against a failure of the nominal site’s Internet access (here Val de Reuil) = have Internet access redundancy
- automatic public IP switchover.
The first step is to configure the multi-site in VCD (the 2 organizations will be paired). This operation is detailed on this page.
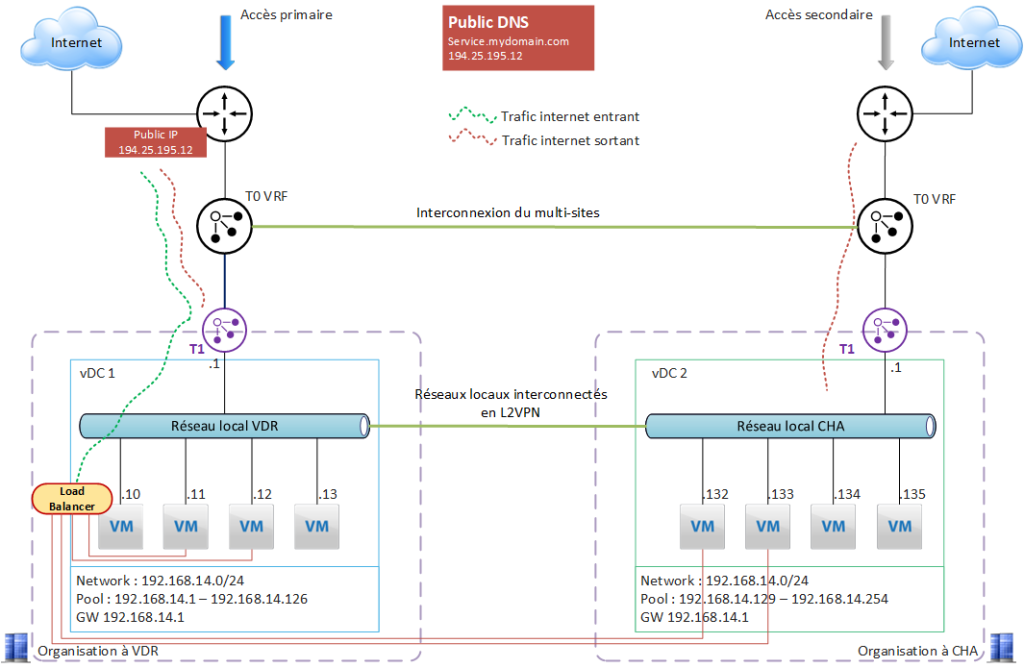
Multisite has been configured and provides :
- the possibility of configuring an L2VPN between the 2 local networks of each site, to enable communication between VMs.
- a logical link between the T0 VRFs, which will manage the automatic switchover of traffic in the event of loss of primary Internet access; each T0 VRF will define the default Internet exit route for each site.
It’s important to configure each site’s network addressing so that it’s compatible and complementary.
Here, an application runs on both sites in active/active mode. The Val de Reuil site’s Internet access is used to expose the service.
The public IP is NATed to the Load Balancer VIP, hosted on a VM (the T1 Load Balancer cannot be used in this case, as a T1 does not “see” the remote local network).
Each VM uses its local access to exit to the Internet.
The local networks of each site are configured so as to be compatible with each other (same subnet, different addressing plan for each site).
VMs are able to talk to each other between the 2 sites, and transactions are synchronized via application mechanisms.
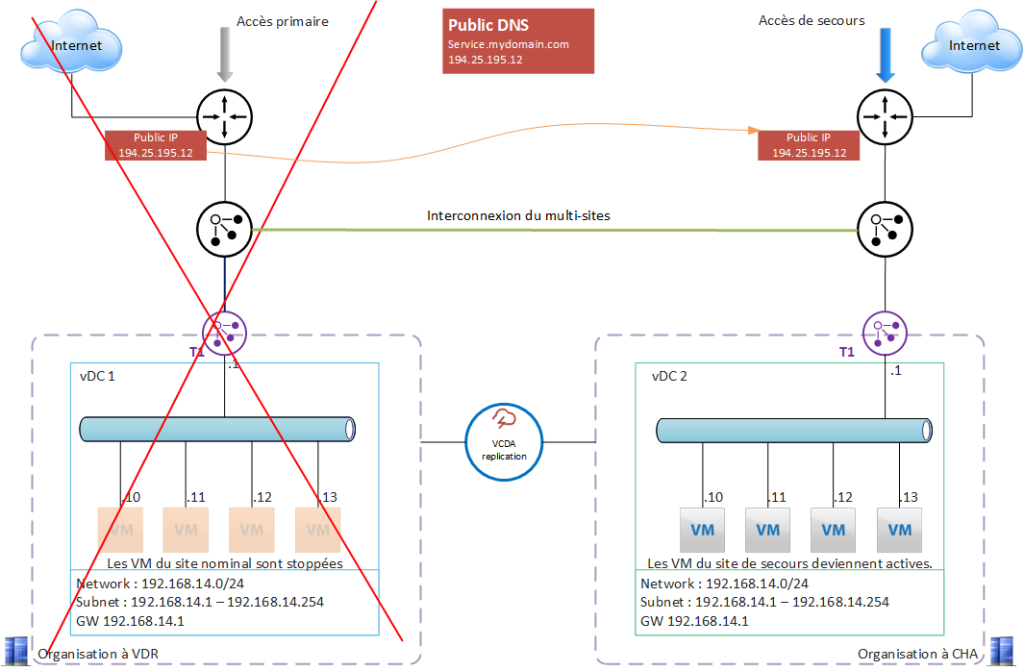
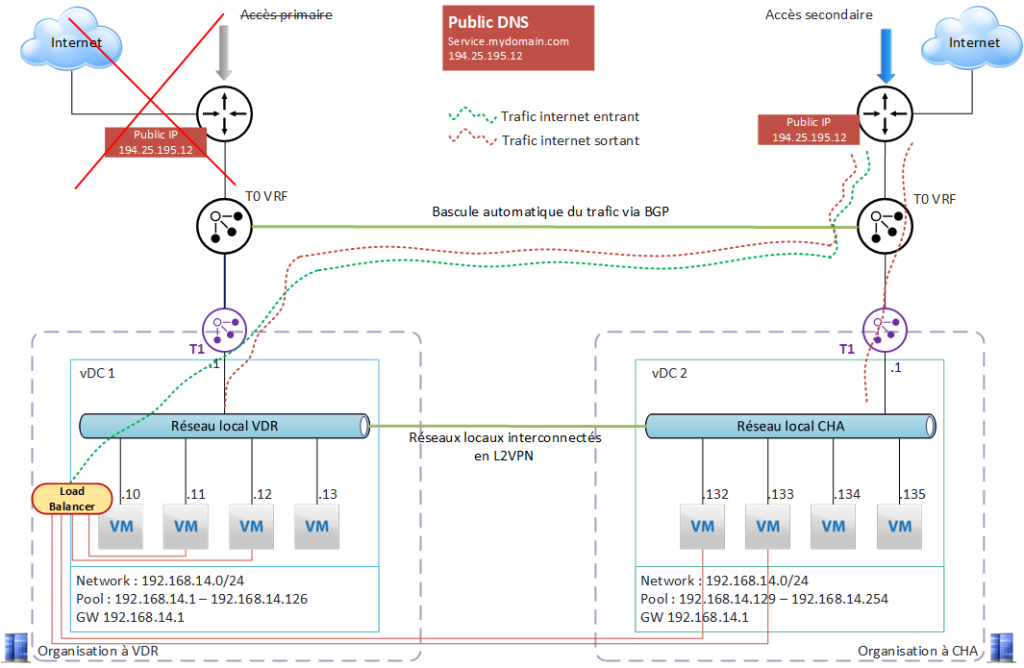
Major problem on the Val de Reuil site: Internet access to the Val de Reuil site is unavailable (backbone incident).
What’s happening on the NSX side?
- Val de Reuil’s T0 VRF no longer communicates with the Internet, and is no longer able to route Internet traffic directly via its main interface.
- Val de Reuil’s T0 VRF “decides” that the default gateway is now Chartres’, and will route all Internet traffic to Chartres’ T0 VRF (BGP failover).
- The public IP exposed on Val de Reuil’s T0 VRF is also switched to Chartres’ T0 VRF, and the BGP switch makes it accessible from Chartres.
The application continues to operate normally.
Internet traffic is handled entirely by the Chartres site, including Val de Reuil VMs.
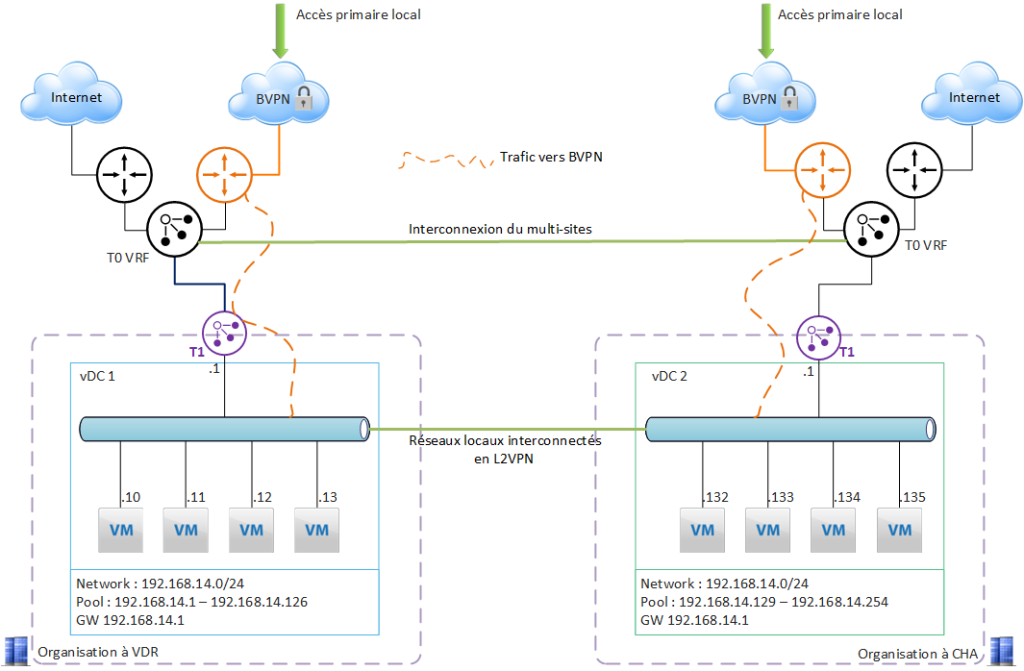
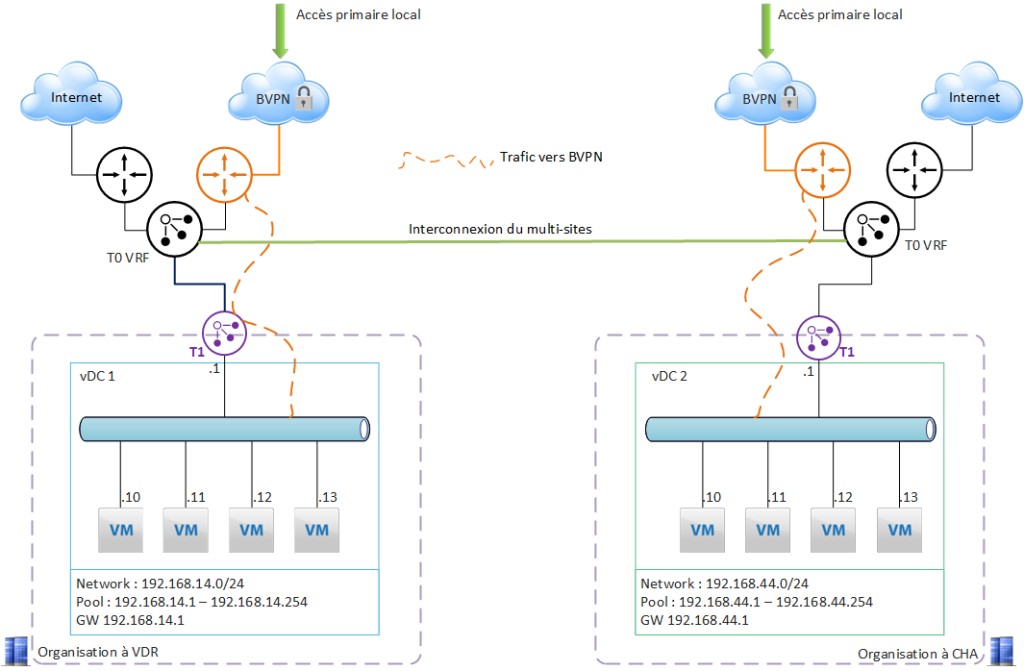
Use case 3 – BVPN access redundancy
The 2 organizations on Val de Reuil and Chartres are initially independent.
The need :
to protect against a failure of BVPN access at one of the 2 sites = to have redundant BVPN access for the site affected by the failure.
The first step is to configure multi-site access in VCD (the 2 organizations will be paired). This operation is detailed on this page
Here we’ll also configure an L2VPN, which enables “extended LAN” communication between the VMs of each site. This feature requires a fine-tuned configuration of the pools on each local network, to avoid IP address overlap.
Mojor incident : BVPN access to the Val de Reuil site is unavailable (backbone incident).
What happens on the NSX side?
- Val de Reuil’s T0 VRF no longer communicates with the BVPN router, and is no longer able to route intranet traffic directly via its main interface.
- Val de Reuil’s T0 VRF “decides” that the default gateway is now Chartres’, and will route all intranet traffic to Chartres’ T0 VRF (BGP failover).
Applications hosted on each site are accessible from the intranet.

use case 4 – BVPN access redundancy
The 2 organizations on Val de Reuil and Chartres are initially independent.
The need :
to protect against a failure of BVPN access at one of the 2 sites = to have redundant BVPN access for the site affected by the failure.
The first step is to configure multi-site access in VCD (the 2 organizations will be paired). This operation is described in detail on this page.
Here, we haven’t created an L2VPN. In this case, the network configurations could be totally identical, or on the contrary totally different.
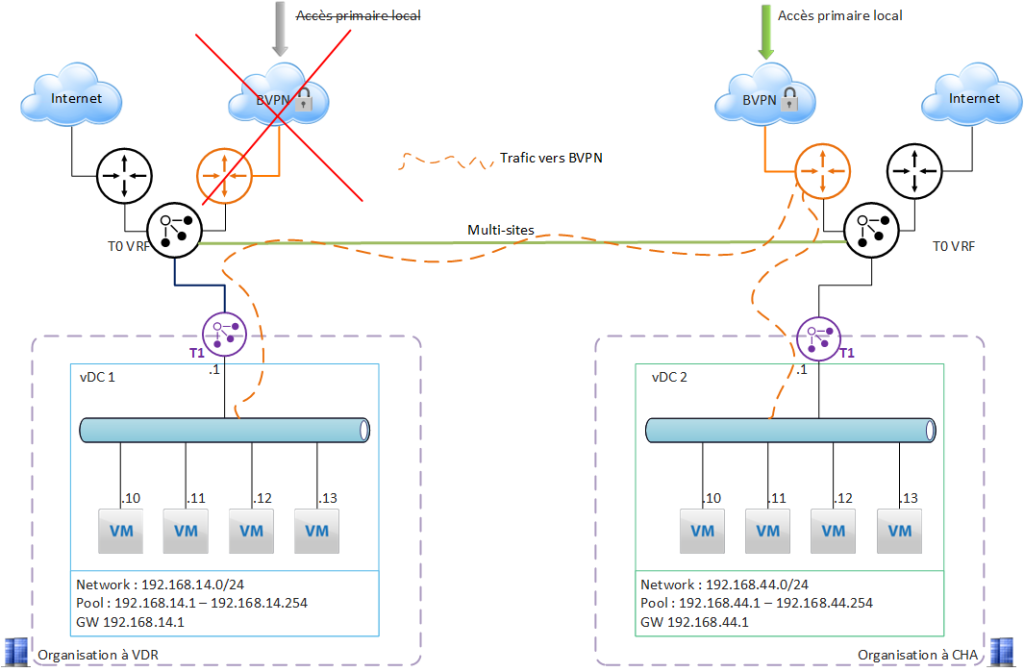
Major incident on the Val de Reuil site: BVPN access to the Val de Reuil site is unavailable (backbone incident).
What happens on the NSX side?
Val de Reuil’s T0 VRF no longer communicates with the BVPN router, and is no longer able to route intranet traffic directly via its main interface.
Val de Reuil’s T0 VRF “decides” that the default gateway is now Chartres’, and will route all intranet traffic to Chartres’ T0 VRF (BGP failover).
Applications hosted on each site are accessible from the intranet.
Use case 5 – vCOD in “Stretched Cluster” mode
The stretched cluster offers the highest level of availability, and can be used to compensate for the loss of a site.
The service uses extended VM profiles, which means that each VM has its own data on each site.
This means that the VM is always up-to-date and available at each site.
In terms of infrastructure, the service is based on an extended cluster deployed at the two Orange datacenters in Val-de-Reuil and Chartres.
A minimum of 4 servers is required on each site (4+4) with a symmetrical configuration.
PCA = Continuity of service => In a nominal situation, workloads are distributed evenly between the 2 sites (50/50), but each site is able to support the entire load. So, in the event of the loss of one site, the second site will be able to redeploy all workloads.
The storage security profile is applied granularly to the VM (the customer can select which of the deployed VMs will automatically restart on the second datacenter).
Sizing and capacity planning must be established to respect the principle of service continuity and enable this switchover (100% of protected VMs must be able to operate on a single site).
Please note !
The control plan is deployed in active/passive mode: a single instance is started on the primary site. If the primary site is lost, the instance is restarted on the secondary site.
Billing
As each site is independent, it is billed independently. Usage is normally tracked and billed on a site-by-site basis, like any other Cloud Avenue organization.
Order
Each organization orders via the normal organization ordering process. Each site has its own organization, and therefore its own contract.