-
Accueil
-
FAQ
-
Fiches Pratiques
-
-
-
-
- Ajouter un Utilisateur NetBackup
- Connaitre son Master Serveur de Backup
- Modifier la langue Portail NetBackup
- NetBackup : Erreurs
- Page d'Accueil NSS
- Portail NetBackup
- Prérequis à la sauvegarde
- Reporting Quotidien
- Restauration de Fichier
- Restauration de VM
- Sauvegarde : Mode Agent B&R via NSS pour l`offre IAAS
- Sauvegarde de VM
- Suppression de Backup
- Swagger NSS
- Swagger NSS avec Postman
-
- Aucun article
-
-
- NSX-T : Comment configurer une solution IPSEC [EN]
- NSX-T : configuration de DNAT [EN]
- NSX-T : configuration de SNAT [EN]
- NSX-T : Création de T1 [EN]
- NSX-T : Créer et configurer un segment overlay Geneve
- NSX-T: Configurer un Pare-Feu de Passerelle/"Gateway Firewall"
- NSX-T: Configurer un Pare-Feu Distribué
- NSX-T: Créer un VPN Ipsec
- Sauvegarde : Conception globale de l'offre VCOD [EN]
- Sauvegarde : Créer une sauvegarde VCOD [EN]
- Sauvegarde : Guide de l'utilisateur pour l'offre VCOD [EN]
- Sauvegarde : Installation de l'agent Netbackup pour Linux [EN]
- Sauvegarde : Installation de l'agent Netbackup pour Windows [EN]
- VCenter : Réinitialiser le mot de passe de cloudadmin [EN]
- VCenter : Snapshot de VM
- VCenter : Storage Vmotion d'une VM
- VCenter: Cloner une VM
- VCenter: Créer une nouvelle VM
- VCenter: Upgrader les Vmware tools sur une VM
-
- Configuration de gabarit ou de personnalisation sur VCD
- Configurer le Multisite
- Découvrir vROPS Tenant
- Droits et Rôles Utilisateurs
- Federation Certificate expiration
- Gestion des Utilisateurs
- Journal des nouvelles fonctionnalités de VCD sur le Pare-feu
- Langue de l'interface vCloud Director
- Plugin VCD Aria OPS pour les clients
- Portail vCloud Director
- VCloud Director
-
Liste des Services (NGP)
-
-
- Aucun article
-
- Aucun article
-
- Aucun article
-
- Aucun article
-
- Aucun article
-
- Aucun article
-
- Aucun article
-
-
-
- Aucun article
-
- Aucun article
-
-
- Aucun article
-
- Aucun article
-
- Aucun article
Dépannage
Dépannage Cluster API
Vérification des PODS
Lorsqu’un problème survient avec Cluster API, la première chose à faire est de vérifier les PODS impliqués dans le fonctionnement de Cluster API.
Vérifiez que ces 4 PODS sont bien en STATUS Running
# kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
capi-kubeadm-bootstrap-system capi-kubeadm-bootstrap-controller-manager-7dc44947-hrmvc 1/1 Running 0 36m
capi-kubeadm-control-plane-system capi-kubeadm-control-plane-controller-manager-cb9d954f5-r8w54 1/1 Running 0 36m
capi-system capi-controller-manager-7594c7bc57-jr75r 1/1 Running 0 37m
capvcd-system capvcd-controller-manager-89758d745-kw4sm 1/1 Running 0 13s
Si l’un de ces PODS n’est pas en status Running, vous pouvez faire deux choses pour recueillir des informations à propos du problème :
- Décrire le POD
- Récupérer les journaux du POD
Example :
# kubectl describe pod capi-controller-manager-7594c7bc57-jr75r -n capi-system
and
# kubectl logs capi-controller-manager-7594c7bc57-jr75r -n capi-system
À noter !
L’outil k9s peut être utilisé pour parcourir le cluster, afficher les journaux et faire des recherches. Reportez-vous à la page KaaS – Outils pour installer
Vérifier le fournisseur CAPVCD
Si des erreurs surviennent concernant la communication avec vCloud Director pendant la création de cluster, la mise à jour de cluster, les opérations d’extension par exemple, il peut s’agir d’un problème avec le fournisseur CAPVCD.
Le POD capvcd-controller-manager dans le namespace capvcd est responsable de ces actions et des erreurs peuvent être trouvées dans ses journaux.
# kubectl logs capvcd-controller-manager-7594c7bc57-jr75r -n capvcd-system
Une option permet d’afficher plus de logs sur la communication avec vCloud Director.
Pour cela lancez la commande suivante :
kubectl set env -n capvcd-system deployment/capvcd-controller-manager GOVCD_LOG_ON_SCREEN=true -oyaml
Cette option étant très verbeuse, n’oubliez pas de retirer cette option une fois le diagnostique terminée, pour cela :
kubectl set env -n capvcd-system deployment/capvcd-controller-manager GOVCD_LOG_ON_SCREEN-
Vérifier les objets API
Cluster API utilise plusieurs types d’objets pour décrire un cluster K8S à gérer.
L’idée pour le dépannage est d’explorer les différents objets pas-à-pas afin de trouver l’objet qui a une erreur au niveau de son statut, sa description ou dans ses logs.
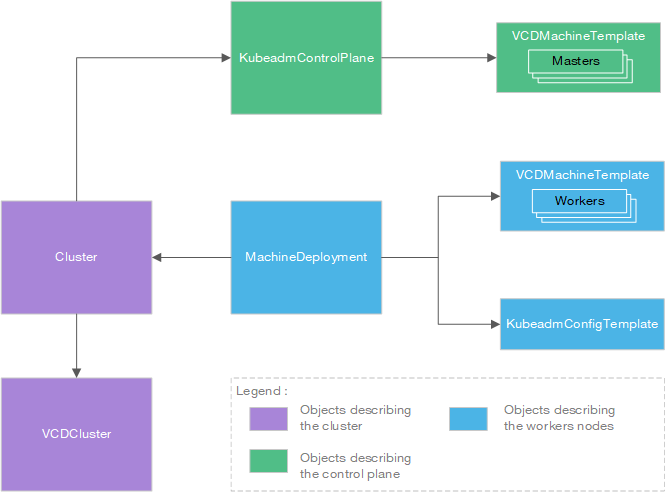
En fonction du composant pour lequel l’erreur survient (noeud de travail, de contrôle ou sur le cluster globalement) il est possible de choisir l’objet à explorer en se reportant au schéma ci-dessus.
- Listez les objets pour trouver le nom exact de l’objet à vérifier
# kubectl get MachineDeployment -A
- Décrire l’objet
# kubectl describe MachineDeployment mycluster-workers-0 -n mynamespace
Répétez les actions 1 & 2 pour l’ensemble des objets afin de trouver l’erreur.
Script d’export des journaux
Un script a été créé par VMware pour exporter les journaux ainsi que quelques informations sur la configuration du cluster.
À noter !
Veillez à bien vérifier le contenu du script avant de l’exécuter.
export KUBECONFIG=[PATH_TO_YOUR_KUBECONFIG]
curl -s https://raw.githubusercontent.com/vmware/cloud-provider-for-cloud-director/[YOUR_CAPVCD_VERSION]/scripts/generate-k8s-log-bundle.sh | bash -
Dépannage du déploiement des noeuds
Voici quelques éléments à contrôler sur le noeuds qui a un problème de déploiement (ne se joint pas au cluster par exemple)
Vérifier l’état sur service kubelet
systemctl status kubelet
Journalctl
journalctl -xeu containerd
journalctl -xeu kubelet
Voici les fichiers à explorer concernant le déploiement des noeuds.
Cloud-init
/var/log/cloud-init-output.log
/var/log/capvcd/customization/status.log
/var/log/capvcd/customization/error.log
containerd
/var/log/containers/*