Dual Site
Aperçu
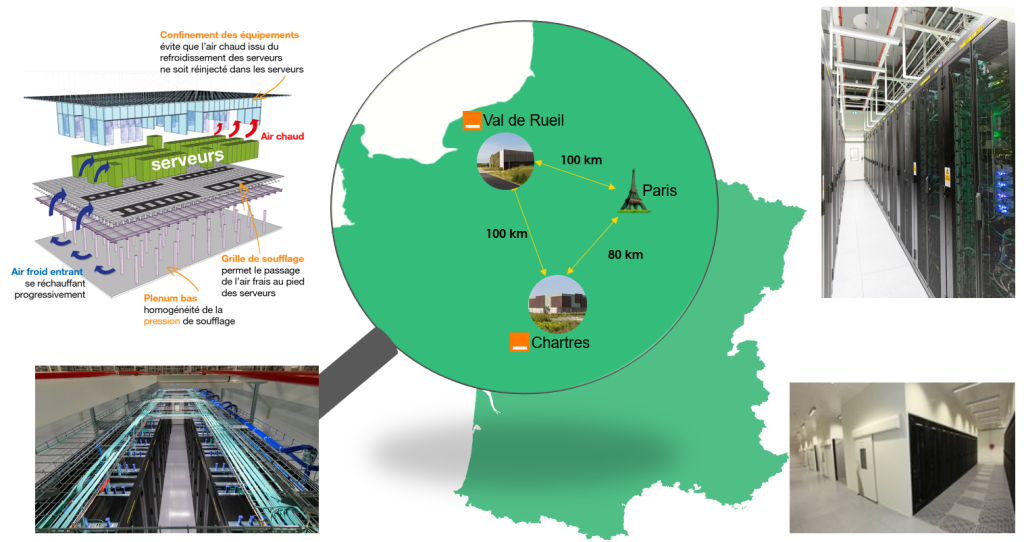
Les datacenters
Présentation
Cloud Avenue (NGP) est déployé sur 2 datacenters situés en France. Ces datacenters sont de conception Orange et intègrent une technologie de refroidissement naturel (« free cooling ») leur permettant d’atteindre un PUE inférieur à 1.3. Un datacenter comporte plusieurs bâtiments, chacun composé de 4 salles totalement indépendantes en énergie, réseau et refroidissement. La conception même des bâtiments garantie une non-propagation d’incendie entre les salles de 4h.
| Datacenter | Code | Nombre de salles hébergeant les charges de travail des clients |
|
Val de Reuil – Normandy 1 |
VDR | 2 |
| Chartres | CHA | 1 |
La solution de sauvegarde utilisée sur la plateforme est hébergée dans une salle différente et indépendante du reste de la plateforme, quel que soit le site.
L’infrastructure de management du site de VDR est repartie sur 3 salles pour un maximum de résilience avec .
Certifications
Nos datacenters sont certifiés :
- ISO 14 001 sur le management environnemental
- ISO 50 001 sur le management de l’énergie
- ISAE 3402/ SOC2 Standard Américain issu de SOX et qui certifie le respect des exigences de sécurité d’accès physique et de fonctionnement
Ils ont également les agréments Mastercard et PCI DSS sur la sécurisation des données bancaires
Interconnexion
Les deux sites sont reliés par un lien physique en fibre noire de 2x100Gbps avec une latence inférieure à 5ms.
Principe et fonctionnalités
Chaque site est indépendant et autonome. Cependant, il est possible d’utiliser simultanément les ressources de chaque site afin de construire des scénarios de reprise d’activité ou de continuité d’activité.
Plusieurs configurations sont possibles, chacune permettant différents cas d’usage, détaillés ci-après.
Bi-site actif/passif
Cette topologie permet la mise en place d’un plan de reprise d’activité (PRA), assez simplement, avec l’outil intégré au portail VCD, VCDA (vCloud Director Availability). La page Réplication de VM fournie toutes les informations à savoir sur le fonctionnement de VCDA. En fonction des politiques de réplications choisies, le RPO peut aller jusqu’à 5 minutes.
Bi-site actif/actif
Cette topologie fournit plusieurs mécanismes de redondance, et permet notamment la mise en place d’un plan de continuité d’activité (PCA), en installant une même application sur les 2 sites.
Il est possible de mettre des applications en actif/actif entre VDR et CHA, avec un RPO à 0, sous conditions :
- Les machines virtuelles utilisent un mécanisme de réplication applicatif (ex. réplication MySQL)
- La réplication est synchrone
Une autre méthode pour obtenir un RPO de 0 pour des applications « business critical » est de les déployer sur une infrastructure vCoD en mode « cluster étendu » (voir Cas d’usage 5).
Cas d’usage
Plusieurs cas d’usages sont supportés dans une configuration bi-site.
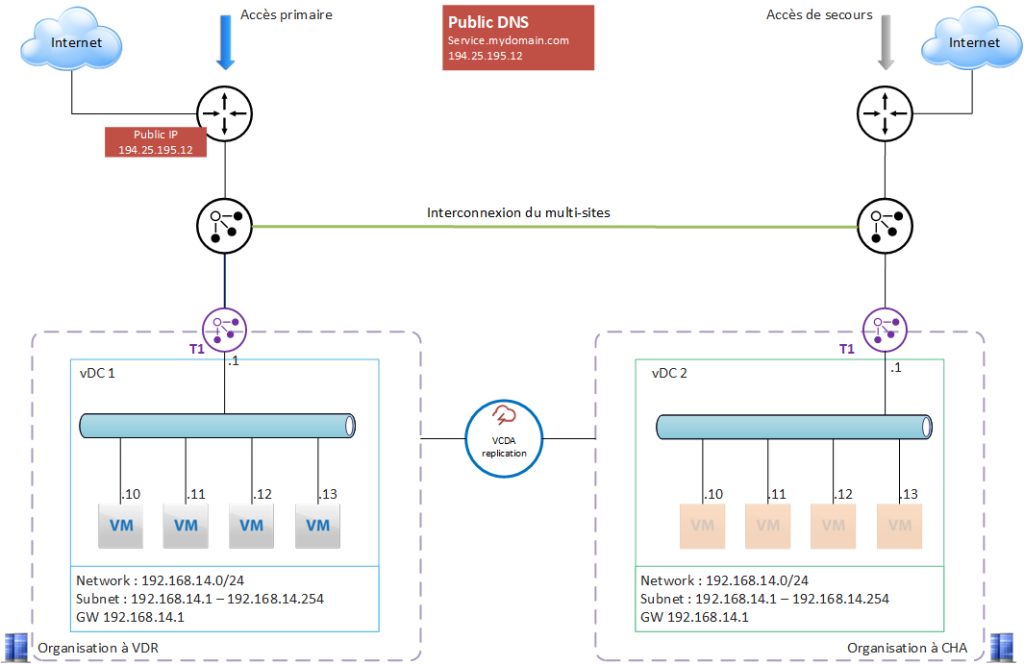
Cas d’usage 1 – PRA
ne application est déployée sur un site nominal, ici VDR. L’application est protégée par VCDA et prête à redémarrer sur le site de secours, ici CHA.
L’application est exposée sur internet et utilise une adresse IP publique, référencée dans un DNS public.
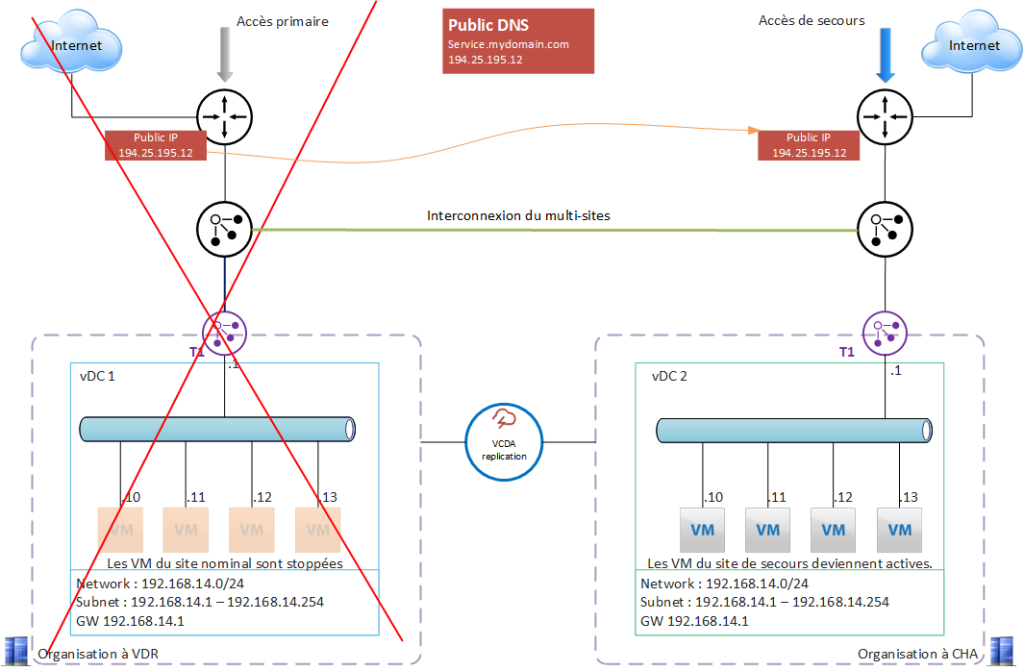
En cas de panne d’un ou plusieurs composants de la plateforme rendant inopérant le service exposé, le client peut déclencher son PRA (configuré avec VCDA) et ainsi rétablir le service dans un délai très court, avec un minimum de perte de données.
Ici, l’IP publique migrera sur le site de secours et permettra au service d’être totalement disponible, une fois la synchro BGP effectuée.
Le retour arrière se fait tout naturellement avec VCDA, sans perte de données, une fois le service sur VDR rétabli. L’IP publique migrera alors vers le site nominal.
Important : choisir des vDC en mode PAYG sur le site de reprise, afin de minimiser la facturation sur le site de secours.
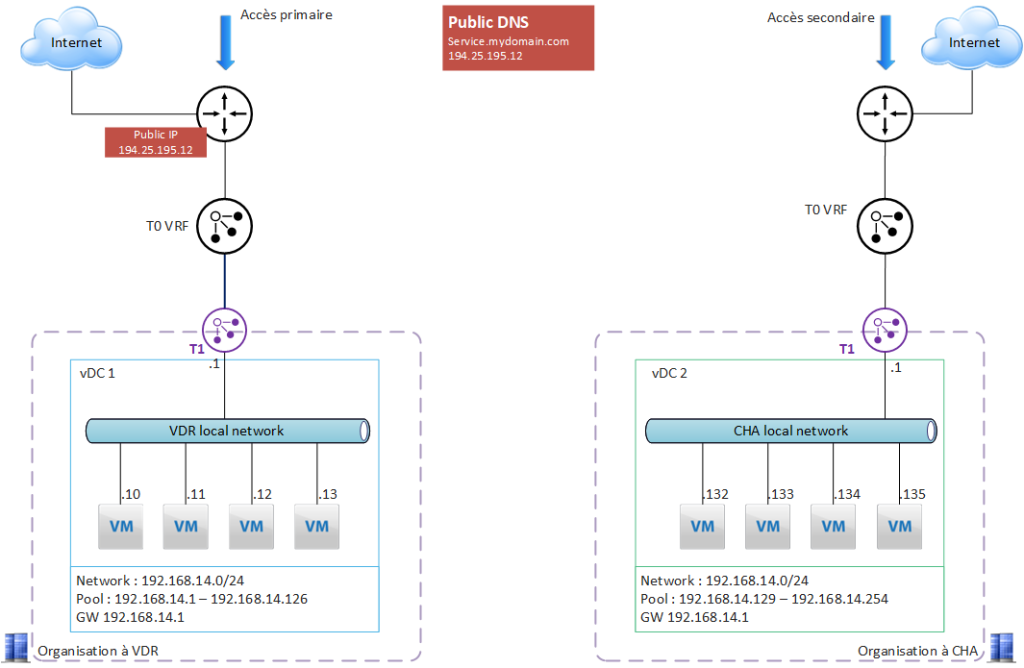
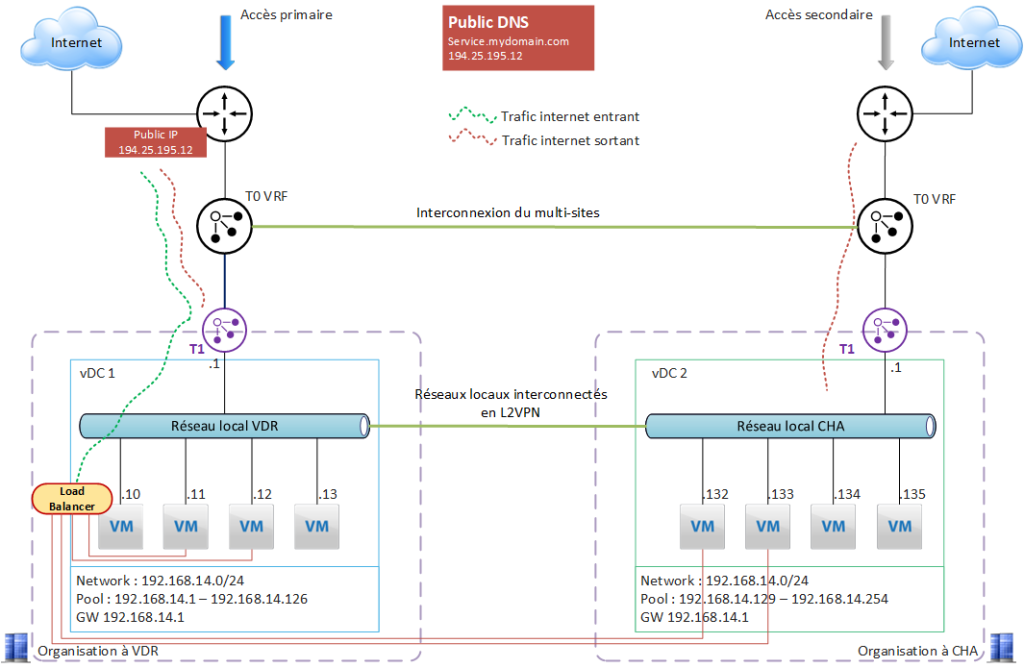
Cas d’usage 2 – Redondance de l’accès internet
Les 2 organisations sur VDR et CHA sont initialement indépendantes.
Les besoins :
- faire communiquer les VM des 2 sites
- se protéger d’une défaillance de l’accès internet du site nominal (ici VDR) = avoir une redondance de l’accès internet
- avoir une bascule automatique de l’IP publique.
La première étape est de configurer le multi-sites dans VCD (les 2 organisations seront appairées). Cette opération est détaillée dans cette page.
Le multisites a été configuré et fournit :
- la possibilité de configurer un L2VPN entre les 2 réseaux locaux de chaque site, afin de permettre la communication entre les VM.
- un lien logique entre les T0 VRF, qui va permettre de gérer la bascule automatique du trafic en cas de perte d’un accès internet primaire ; chaque T0 VRF va définir la route par défaut de sortie sur internet pour chaque site.
Il est important de bien configurer l’adressage réseau de chaque site afin qu’il soit compatible et complémentaire.
Ici, une application fonctionne sur les 2 sites en actif/actif. L’accès internet du site de VDR est utilisé pour exposer le service.
L’IP publique est NATée sur la VIP du Load Balancer, hébergé sur une VM (le Load Balancer de la T1 ne peut pas être utilisé dans le cas présent, car une T1 ne « voit » pas le réseau local distant).
Chaque VM utilise son accès local pour sortir sur internet.
Les réseaux locaux de chaque site sont configurées de façon à être compatibles entre eux (même subnet, découpage du plan d’adressage par site).
Les VM sont capables de dialoguer entre-elles entre les 2 sites, et la synchronisation des transactions est réalisées via des mécanismes applicatifs.
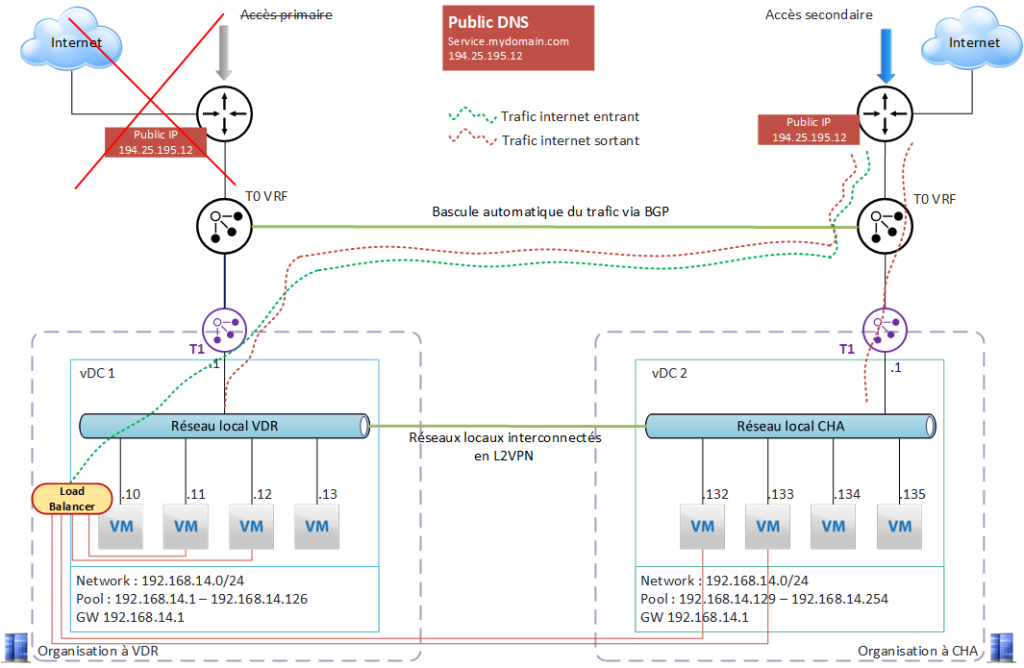
Incident majeur sur le site de VDR : l’accès internet du site de VDR est indisponible (incident backbone).
Que se passe-t-il côté NSX ?
- La T0 VRF de VDR ne communique plus avec internet, et n’est plus capable de router le traffic internet directement via son interface principale.
- La T0 VRF de VDR « décide » que la passerelle par défaut est maintenant côté CHA, et va router tout le trafic internet vers la T0 VRF de CHA (bascule BGP)
- L’IP publique exposée sur la T0 VRF de VDR est aussi basculée sur la T0 VRF de CHA, et la bascule BGP la rend accessible à partir de CHA.
L’application continue à fonctionner normalement.
Le trafic internet est entièrement assuré par le site de CHA, y compris pour les VM de VDR.
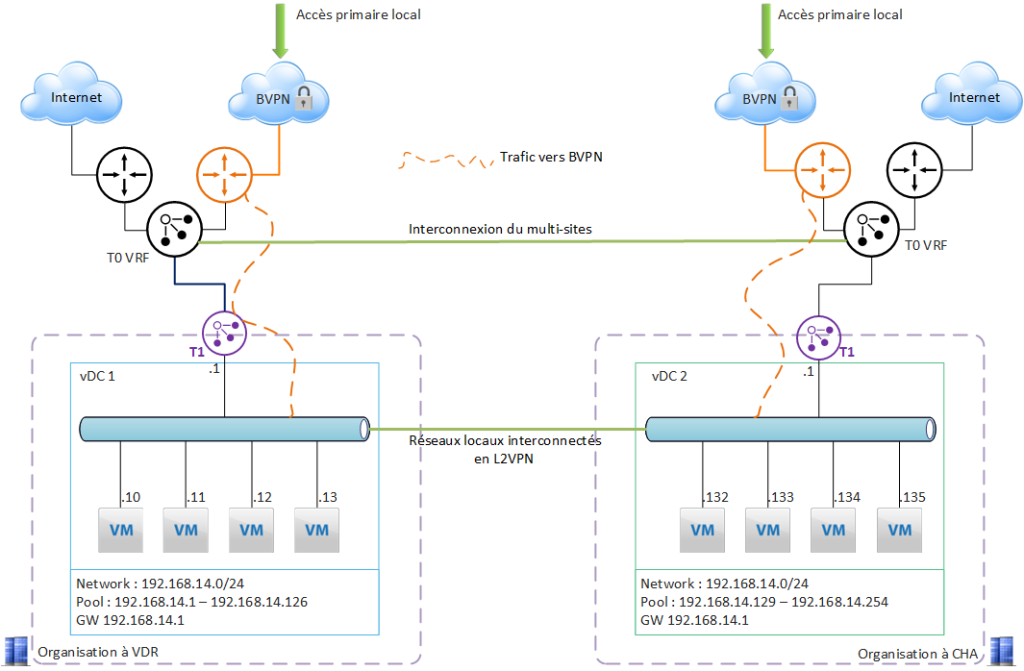
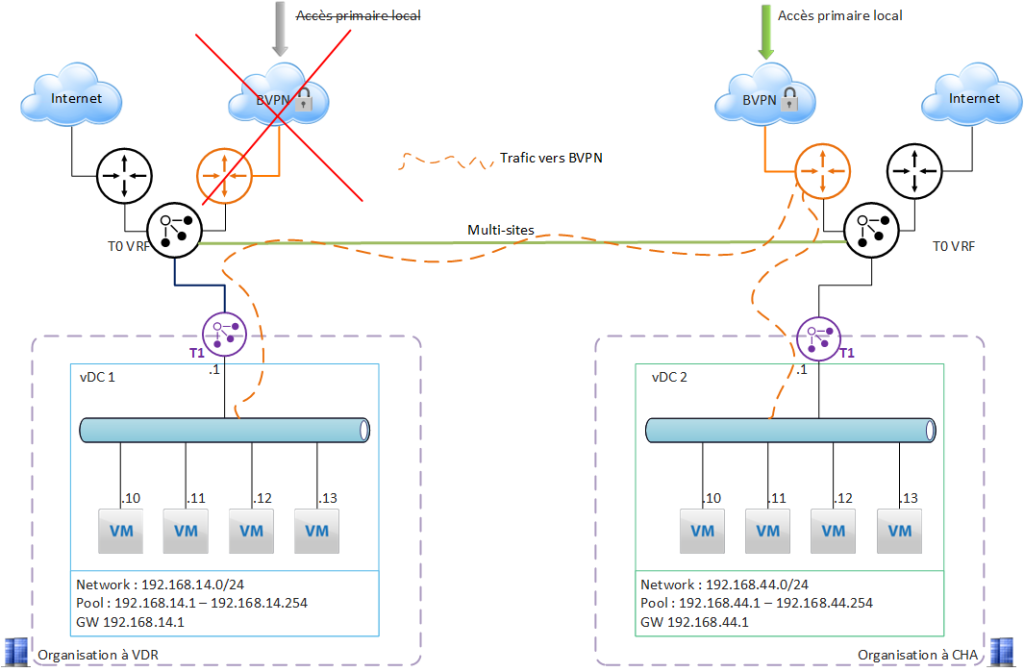
Cas d’usage 3 – Redondance de l’accès BVPN
Les 2 organisations sur VDR et CHA sont initialement indépendantes.
Le besoin :
se protéger d’une défaillance de l’accès BVPN d’un des 2 sites = avoir une redondance de l’accès BVPN pour le site impacté par la panne.
La première étape est de configurer le multi-sites dans VCD (les 2 organisations seront appairées). Cette opération est détaillée dans cette page
Ici on va aussi configurer un L2VPN, ce qui permet d’avoir du « LAN étendu » et de permettre la communication entre les VM de chaque site. Cette fonctionnalité nécessite une configuration ajustée des pools de chaque réseau local, afin d’éviter le recouvrement d’adresse IP.
Incident majeur sur le site de VDR : l’accès BVPN du site de VDR est indisponible (incident backbone).
Que se passe-t-il côté NSX ?
- La T0 VRF de VDR ne communique plus avec le routeur BVPN, et n’est plus capable de router le traffic intranet directement via son interface principale.
- La T0 VRF de VDR « décide » que la passerelle par défaut est maintenant côté CHA, et va router tout le trafic intranet vers la T0 VRF de CHA (bascule BGP)
Les applications hébergées sur chaque site sont accessibles de l’intranet.

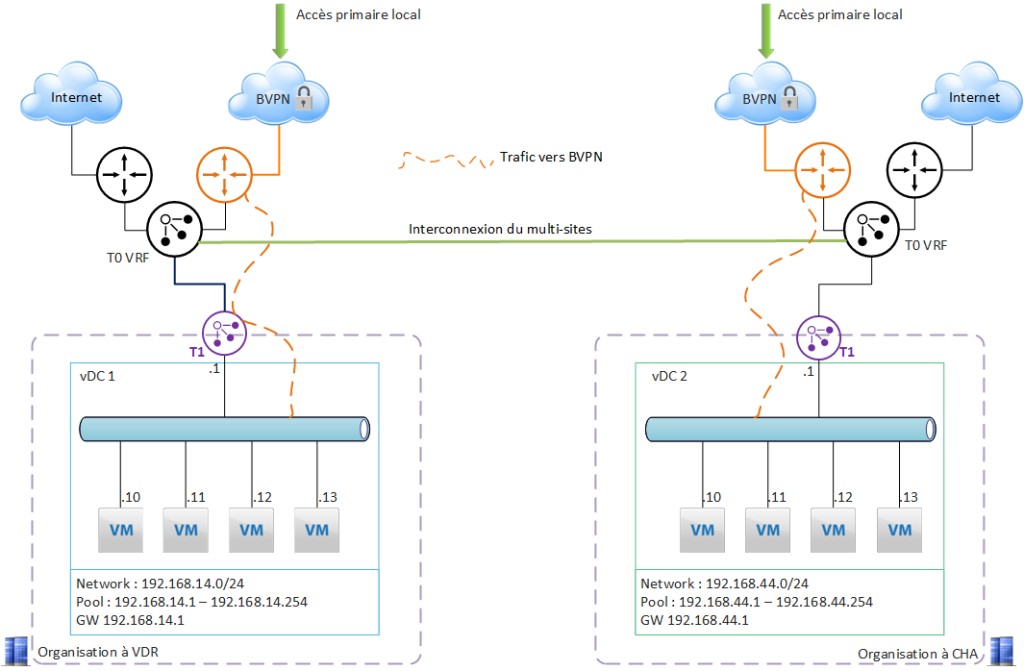
Cas d’usage 4 – Redondance de l’accès BVPN
Les 2 organisations sur VDR et CHA sont initialement indépendantes.
Le besoin :
se protéger d’une défaillance de l’accès BVPN d’un des 2 sites = avoir une redondance de l’accès BVPN pour le site impacté par la panne.
La première étape est de configurer le multi-sites dans VCD (les 2 organisations seront appairées). Cette opération est détaillée dans cette page.
Ici, nous n’avons pas créé de L2VPN. Dans ce cas, les configurations réseau pourraient être totalement identiques, ou au contraire totalement différentes.
Incident majeur sur le site de VDR : l’accès BVPN du site de VDR est indisponible (incident backbone).
Que se passe-t-il côté NSX ?
- La T0 VRF de VDR ne communique plus avec le routeur BVPN, et n’est plus capable de router le traffic intranet directement via son interface principale.
- La T0 VRF de VDR « décide » que la passerelle par défaut est maintenant côté CHA, et va router tout le trafic intranet vers la T0 VRF de CHA (bascule BGP)
Les applications hébergées sur chaque site sont accessibles de l’intranet.
Cas d’usage 5 – vCOD en mode « Stretched Cluster »
Le cluster étendu présente le plus haut niveau de disponibilité et permet de palier la perte d’un site.
Le service utilise des profils de VM étendus, ce qui signifie que chaque VM dispose de ses données sur chaque site.
Ainsi, la VM est actualisée et disponible en permanence sur chaque site.
Au niveau infrastructure, le service s’appuie sur un cluster étendu déployé sur les deux datacenters Orange de Val-de-Reuil et Chartres.
Un minimum de 4 serveurs est requis sur chaque site (4+4) avec une configuration symétrique.
PCA = Continuité de service => En situation nominale, les workloads sont répartis entre les 2 sites de manière équilibrée (50/50) mais chaque site est en mesure de supporter l’ensemble de la charge. Ainsi, en cas de perte d’un site, le second site pourra redéployer l’ensemble des workloads.
Le profil de sécurisation de stockage est applicable granulairement à la VM (le Client peut sélectionner laquelle des VM déployées redémarrera automatiquement sur le second datacenter).
Le dimensionnement et le capacity planning devront être établis pour respecter le principe de continuité de service et permettre ce basculement (100% des VMs protégées doivent pouvoir fonctionner sur un seul site).
À noter
Le plan de contrôle est déployé en mode actif/passif : une seule instance est démarrée sur le site primaire. En cas de perte du site primaire, l’instance est redémarrée sur le site secondaire.
Facturation
Chaque site étant indépendant, il est facturé de manière indépendante. Les usages sont normalement remontés par site et facturés, comme n’importe quelle organisation Cloud Avenue.
Commande
Chaque organisation se commande via le processus de commande normal d’une organisation. A chaque site correspond une organisation, et donc un contrat.