Dedicated Cluster
Introduction
Cloud Avenue’s Dedicated Cluster offering is a private cloud infrastructure solution that provides customers with fully dedicated physical servers within Orange Business’s shared platform. It is designed to meet specific business constraints, particularly for the use of proprietary software licenses (such as Microsoft SPLA) and to satisfy strict compliance and security requirements.
This solution removes barriers to cloud adoption for businesses with critical workloads by ensuring complete hardware isolation. It enables optimized use of existing licenses in a sovereign and controlled cloud environment.
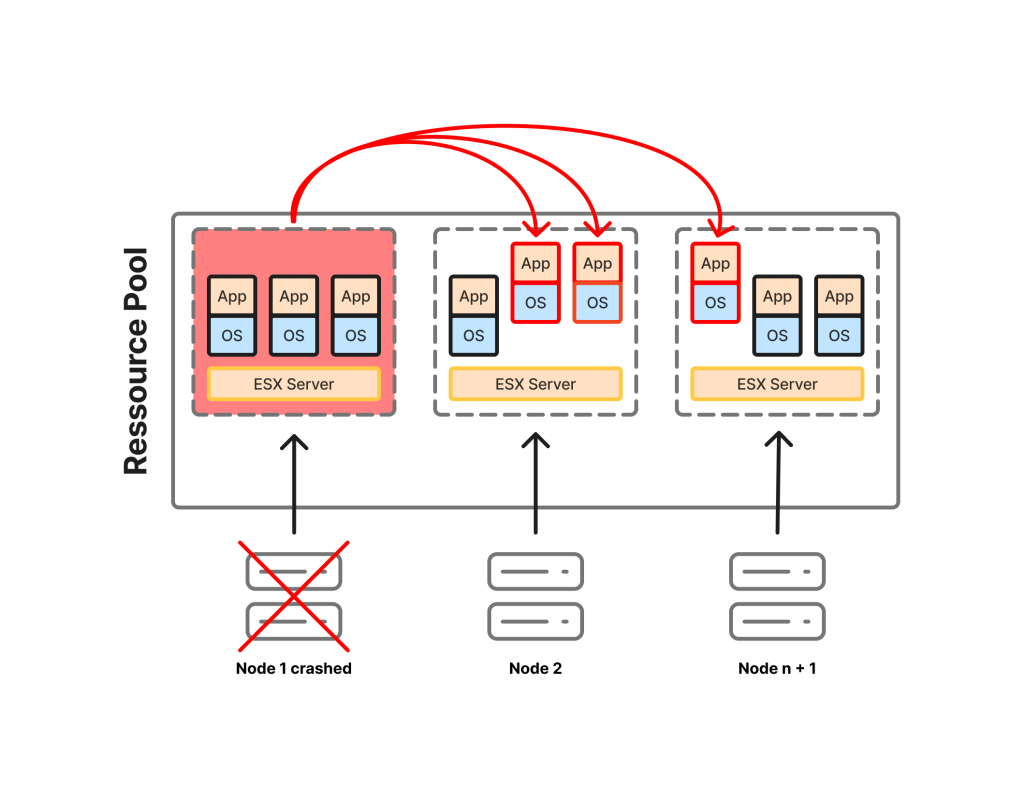
Global overview
The service is based on the privatization of a group of physical servers (minimum 3 hosts) on which a dedicated Provider vDC (pVDC) is built. The customer can then create one or more Virtual Data Centers (vDC) on this exclusive hardware base, which guarantees that their virtual machines (VMs) do not share the same physical hosts as other customers (no colocation).
Resource allocation is managed via Reservation Pool mode, which offers several advantages:
- Burst access: VMs can consume more resources than those guaranteed to them, as long as capacity is available at the cluster level.
- Fine control: The customer can precisely adjust the guaranteed CPU and RAM percentage, as well as the vCPU frequency.
- Consolidation management: The customer controls their own consolidation and overbooking ratio.
More information about the “Reservation Pool” resource allocation model is available on the VMware website.
Server configurations
Clusters are composed of latest-generation blade servers, with full boot-from-SAN capability. The minimum configuration is 3 servers per cluster, with a maximum limit of 32 ESXi nodes. It is recommended that servers be distributed across multiple chassis to increase availability.
Be aware !
This dimensioning is the responsibility of the Customer.
Capacity management
Capacity management is the responsibility of the Customer. Orange Business Services will provide the Customer with VMware indicators to monitor the overall performance of the cluster, as well as the performance of the VMs.
Important :
- The decision to change the cluster size is the responsibility of the Customer
- The sizing of the dedicated cluster must take into account the possibility of losing a blade without impacting the proper functioning of the hosted service
Other resources (storage, network, etc.) are provisioned according to the standard Flexible Computing Advanced process and billed according to the current price list.
Available configurations
The following hardware configurations are available:
| Configurations | CPU | RAM |
| M 16-512 | 1x Intel Xeon Gold 6526Y (16 coeurs, 2,8-3,9 GHz) | 512 GB |
| M 32-1024 | 1 x Intel Xeon Gold 6548Y+ (32 coeurs, 2,5-4,1 GHz) | 1024 GB |
| M 64-2048 | 2 x Intel Xeon Gold 6548Y+ (64 coeurs, 2,5-4,1 GHz) | 2048 GB |
The architecture is designed to tolerate the failure of one or more servers (n-1 or n-2) in order to ensure service continuity during maintenance operations.
Previous server configurations (no longer available for order):
| Features | Type 1 | Type 2 |
| CPU | Intel xeon Gold | Intel xeon Gold |
| CPU Frequency | 2,2 GHz | 3 GHz |
| Number of CPU | 2 | 2 |
| Number of core per CPU | 28 | 24 |
| Number of physical cores/blade | 56 | 48 |
| RAM | 576 Go | 276 Go |
| Usage | Dedicated VMware Cluster | Dedicated VMware Cluster |
Deployment topologies
Three deployment topologies are available to meet different levels of availability and business continuity requirements:
| Topology | Description | Use case |
|---|---|---|
| Mono-room | A single cluster deployed in a single room in the data center. Minimum configuration of 3 nodes. | Non-critical development, testing, or production environments. |
| Dual Room (High availability) | A single VMware cluster in two different rooms. Uses synchronously replicated storage for a theoretical RPO of zero. Failover is automatic via VMware HA/DRS. Minimum configuration of 4 nodes. Only for DC in Val de Reuil. | Critical applications requiring high availability and uninterrupted service continuity. |
| Dual Site (Disaster Recovery) | Replication of VMs between the Val de Reuil and Chartres sites in DRaaS (Disaster Recovery as a Service) mode using the vCloud Director Availability (VCDA) tool. | Disaster recovery plan (DRP) with service interruption during failover. |
Dedicated storage
The principle of isolation also applies to storage. Each Dedicated Cluster is associated with dedicated LUNs (Logical Unit Numbers) that are only mounted by the customer’s pVDC.
- Replicated storage: Dual Room topologies use a replicated datastore to ensure high availability.
- Performance classes: Several classes are available, such as Silver, Gold, and P3K.
- Sizing: The maximum size of a datastore is 10 TB, but a customer can have multiple datastores.
Compute layer configuration
The customer retains control over the logical configuration of their cluster:
- Affinity/anti-affinity rules: Customers can define their own rules via the vCD portal to restrict the placement of VMs on certain hosts, for example for licensing or performance reasons.
- DRS (Distributed Resource Scheduler): Enabled in fully automated mode by default for VM load balancing.
- VMware High Availability (HA): Fault tolerance is configured by default to n-1 (failure of one server). It can be adjusted to n-2 for more stringent requirements.
OS license management
The offer is optimized for managing software license costs:
- Optimized VM placement: Affinity rules allow VMs to be grouped by operating system type (e.g., Windows or Linux) on specific ESXi host groups.
- BYOL (Bring Your Own License) support: Customers can use their own licenses.
Certified operating systems include Windows, RedHat, SUSE, Debian, Ubuntu, and Rocky Linux.
Monitoring and metrology
The customer has several tools available to monitor the performance and usage of their cluster:
- Aria Operations: Provides detailed metrics on cluster and VM performance, as well as access to logs.
- Usage Meter: Collects consumption data for VMware products. This feature is not available by default, but it can be requested via a ticket to the support.
Subscription and provisioning
Subscription is via the Orange Business Cloud Store platform, through the service catalog under the “Resources” tab. Once the order has been confirmed, cluster deployment and expansion orchestrated by Orange teams. This includes server reservation, storage provisioning, network configuration, and integration with monitoring tools.
Order tile from the Cloud Store.
Pricing and billing
Billing is monthly and based on the number and configuration of physical servers reserved by the customer.
- Model by topology: The calculation formula varies depending on whether the cluster is in Single Room or Dual Room/Dual Site mode.
- Pro rata temporis: Any server added during the month is billed pro rata based on the number of days of activity.
Capacity management and maintenance
Cluster capacity management is the responsibility of the customer. Orange Business provides all necessary VMware metrics via Aria Operations to enable the customer to make informed decisions about adding or removing servers. The fault-tolerant design (n-1 or n-2) ensures that maintenance operations (patch deployment, updates) can be carried out without impacting production.
Termination
The service is terminated via a manual process in which the name of the vDC and the dedicated cluster must be specified. This action can be performed via change requests.
Support
Support is provided by Orange Business teams. Customers can monitor their environment via the portals made available to them (Aria Operations) and open support tickets.