Building a resilient workload
This article describes resiliency design & features offered by Flexible Engine, and share good practises & example to respect for any workload design for High Availibility
A Multi Region / Multi AZ design
Design
3 AZ per Region
Standard design of Orange Business Service Public Cloud is 3 Availability zones [ie. AZ] based to
- Optimize your applications via a distributed architecture;
- Replicate your data, and implement your disaster recovery / business continuity plan;
- Reduce the impact of single point of failure.
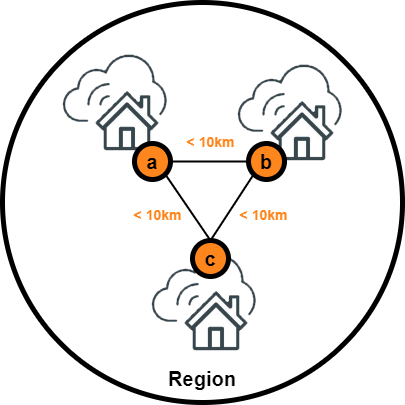
Our commitments
- One AZ = One (or more) DC (Data Center)
- Dual connectivity from external
- Private high performance backbone between AZ to enable LAN workload
- Less than 10km between each DC to minimize latency (less than 1.2ms between AZ), but enough to face local disaster
Flexible Engine
Available Region
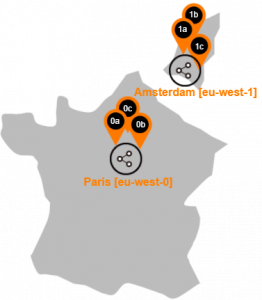
Flexible Engine regions and its Availability Zones
Current High level design
Based on an extended Openstack design at the region level, each Avalibilty Zone [AZ] is matching specific DC to cover disaster in one place
- External Connectivity (Internet by default, Private network as option) lands in AZ a & b to offer High Available access, any time
- Extended Virtual network (Virtual Private Cloud & Subnets) without latency inside region to enable workload geo-distribution
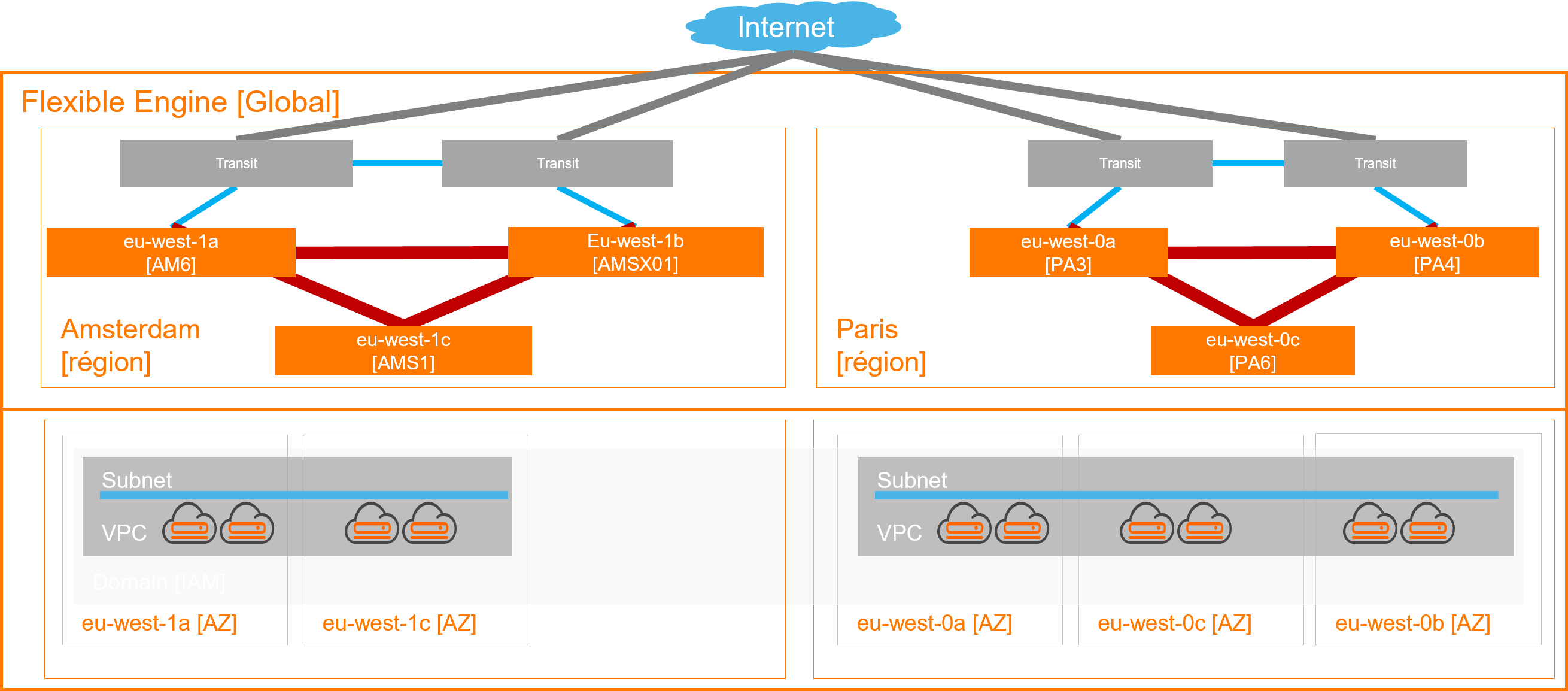
This architecture propose native capacity for user to distribute their workload on that network across physical Datacenter, hiding the compexity behind the Virtual Private Cloud, enabling any High Level design for any customer workload on top of the Flexible Engine Region
How to evaluate a resilient approach for Cloud workload
On Flexible Engine, the level of resilience is to be defined on several levels according to any Public Cloud model
|
Resilience |
Définition |
Owner |
|
Cloud Service |
The Cloud service is designed to be resilient in multi AZ within a region |
Orange |
|
Cloud Ressource |
Cloud resources deployed provide a level of resilience to be identified: AZ > Regional > Global |
Orange |
|
Application workload |
The application must be designed to take advantage of the 2 previous plans, in accordance with good practice |
Users |
Cloud Services resiliency within Paris region
Resiliency per service
NB : inventory below is based on Paris region, Amsterdam region is being upgraded for availability
Apply to Flexible Engine service, we can consider 3 different categories relying on their reliency model :
- Some Services are natively resilient. Their design implement a native High Availibilty, distributed between Availibility Zone in the region, without any action from the user providing the such Cloud ressource. As an example, the ELB building Load balancing between ECS backend is build on a HA configuration between AZa & AZb
- Some Services propose resiliency as an Option. This mean user can choose between a standalone mono AZ configuration and a HA multi AZ one (setup by default). In case of HA configuration, user can place the Cloud ressource building the service in several AZ. As an example, the RDS service propose some Master/Slave configuration in one click; enabling to place Master in one AZ and Slave in another one.
- Basic Compute (ECS) and Storage (EVS) implement AZ local HA (thanks to autorecovery feature for ECS or 3 copy concept for EVS). But user can leverage the extended Virtual Network to build its own workload , and distribute compute Nodes accros AZ in the region. These Services are considered as Enabler for workload resiliency
|
Provisionning |
Item |
Service |
Resiliency |
|||
|
Enabler |
Option |
Native |
||||
|
1 |
Connection to the service |
Management |
IAM |
√ |
||
|
2 |
Creation of the network base & associated services |
Network |
VPC |
√ |
||
|
ELB |
√ |
|||||
|
DC |
√ |
|||||
|
DNS |
√ |
|||||
|
NAT GW |
√ |
|||||
|
3 |
Provisioning of computing resources and storage |
Compute |
ECS |
√[1] |
||
|
BMS |
√ |
|||||
|
CCE |
√[4] |
|||||
|
Storage |
EVS |
√ [5] |
||||
|
4 |
Provisioning of shared storage resources |
Storage |
SFS OBS |
x[2] |
||
|
√[3] |
||||||
|
sDRS |
√[1] |
|||||
|
5 |
Provisioning of managed resources |
Database |
RDS |
√[4] |
||
|
DDS |
√[4] |
|||||
|
Application |
DCS |
√[4] |
||||
|
DMS |
√[4] |
|||||
|
6 |
Adding security services |
Security |
Anti-DDoS |
√ |
||
|
KMS |
√ |
|||||
|
WAF |
√ |
|||||
[1] User should locate its ECS in one AZ of the region. Locally in the AZ, ECS availibility rely on autorecovery (ie. relocate & restart after Hypervisor failure, possible only for flavor without local disk, like D series)
[2] SFS propose NAS feature with different class of storage :
- SFS Capacity oriented : volume created are located in eu-west-Xa only, even if the volume can be mounted in enay ECS of the region, thanks to the VPC/Subnet cross AZ feature
- SFS Turbo : volume cerated can be located in any AZ of the region, with a lolca resiliency design.
[3] OBS backend storage implement a 3 copy mechanisms allowing resiliency (check EVS description below, mechanism is identical). Different class of Storage are available
- Online storage (Standard & Warm) propose a Multi-AZ resiliency (1 copy per AZ) and a Mono-AZ resiliency (3 copy in AZ eu-west-Xa)
- Offline storage (Cold) propose only Mono-AZ resiliency (3 copy in AZ eu-west-Xa)
[4] All those services propose resiliency as an option with cross AZ configuration activated by default. User can decide to unconfigure HA to save mony (for test purpose as example)
[5] EVS propose some virtual disk in the AZ where the user locate the ECS. As a consequence, EVS propose a Mono AZ resiliency with a 3 copy mechanism, check EVS Three-Copy Redundancy for more detail
Focus on backup
|
Service |
Backup & Restore object |
Functions |
Data localisation |
Cross Region Replication |
Support OBS 3AZ |
|
VBS [*] |
Volume EVS disk (system or data disk) |
|
OBS Mono AZ in eu-west-Xa |
Not planned[*] |
Not planned[*] |
|
CSBS [*] |
|
|
OBS Mono AZ in eu-west-Xa |
Not planned[*] |
Not planned[*] |
|
CBR (CSBS/VBS evolution) |
|
Cloud Server Backup:
Cloud Disk Backup:
SFS Turbo Backup:
|
OBS Mono AZ in eu-west-Xa for any Vault created before 2022Q4 OBS Multi AZ for any Vault created after 2022Q4 |
Live |
Live for any Vault created after 2022Q4 |
|
FAB |
|
|
OBS Multi AZ (eu-west-0 or eu-west-1) |
Live |
Live |
[*] CBR is the next generation Service to federate all backup services : CSBS will be replaced by CBR Server Backup & VBS will be replaced by CBR Volume Backup. So good practis is to use CBR for any new workload
Tips & Good practice
[1] ECS/EVS/sDRS
- ECS and their EVS volumes are provisioned in a given AZ, with local AZ resiliency (Auto-recovery ECS & distributed block storage, check EVS Three-Copy Redundancy for more detail )
- Auto Scaling Group on multi AZ when possible for your workload hosted on ECS, with ELB integration to manage the flow
- sDRS is only available on eu-west-0a & 0b! Depending the backups Service you are using (if backups are stored on OBS mono-AZ, in eu-west-0a, check above), the sDRS master has to be provisioned on eu-west-0b
[2] SFS/SFS Turbo
- SFS Turbo is available on each AZ (SFS only available on eu-west-0a ) but only locally resilient even if visible from each AZ (via NFS) [Roadmap evolution & workaround provision in progress].
[3] OBS
- OBS is available in Mono-AZ and multi-AZ for the Online classes (Standard & Warm) while the Offline class (Cold) is Mono-AZ [evolution Roadmap].
- It is recommand to migrate from Mono-AZ OBS to a multi-AZ OBS, thanks to obstutil tool. Check the obsutil online help to download, setup and replicate a bucket
- CSBS & VBS Backup services (or any backup feature integrated with managed services, consider RDS backup as an example) still use OBS mono-AZ (on Xa). As they are soon deprecated, prefer to use CBR, but becarefull to (re)create the Backup Vault after the release date (check Roadmap). If you are using CSBS/VBS, you can refer to Migrating Resources from CSBS/VBS to migrate to CBR
[4] Managed services (CCE, RDS, DDS, DCS, etc…)
- Enable HA functionality with respect to localization
- Master/Slave cluster services (RDS type): master on eu-west-0b or 0c
- Services with quorum (type CCE, DDS, DCS): node distribution on the 3 AZ
- Auto Scaling Group on multi AZ when possible for your workload hosted on CCE
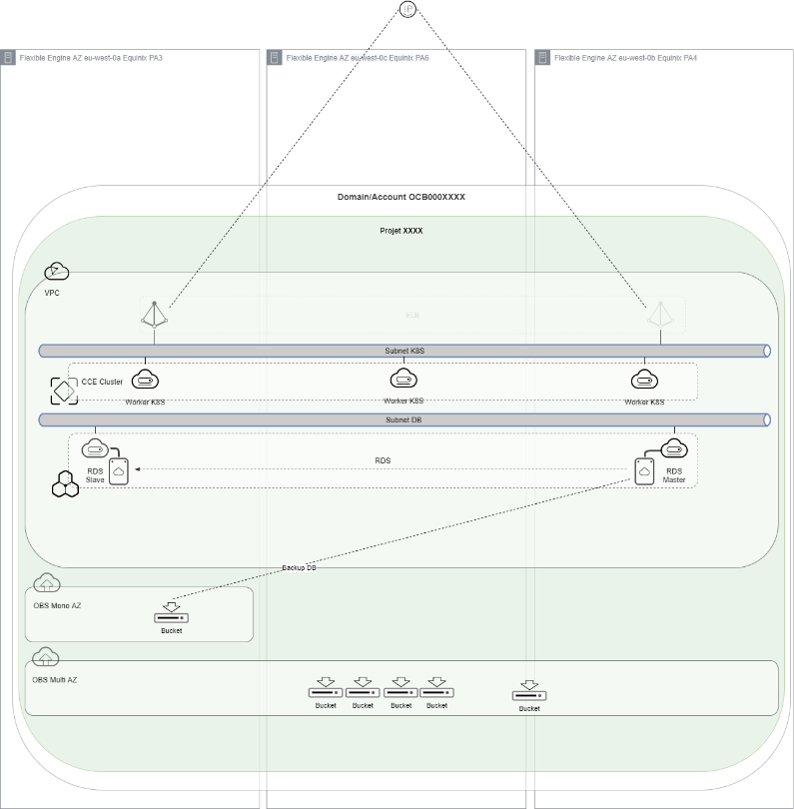
User workload (Paris region as example)
legacy to Cloud workload
Characteristics
- IaaS
- Non-resilient design by default
Solution
- Backup
- sDRS
Recommendation
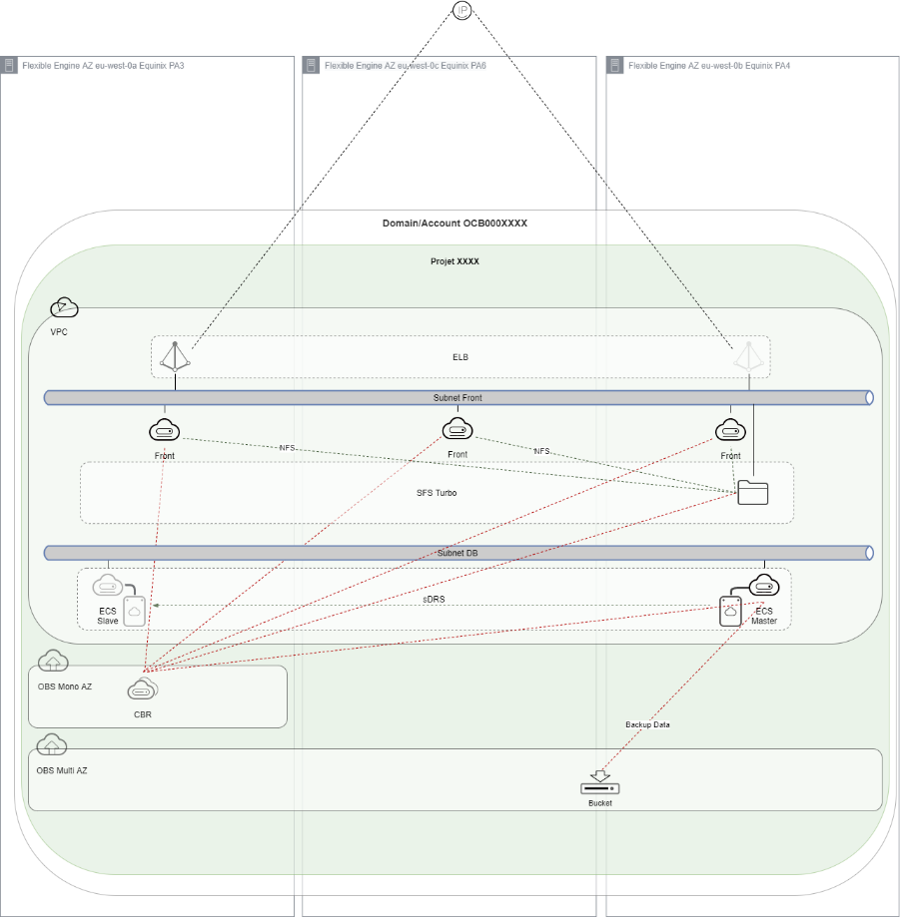
- Workload on AZ eu-west0-b or eu-west0-c
- Backup with CBR or FAB (OBS Multi AZ)
- sDRS with master on AZ eu-west0-b & slave on eu-west-0a
- Enable Auto Scaling Group on multi AZ when possible for your workload hosted on ECS
Data in the Cloud
Characteristics
- Massive data storage
Solution
- OBS S3 object storage
Recommendation
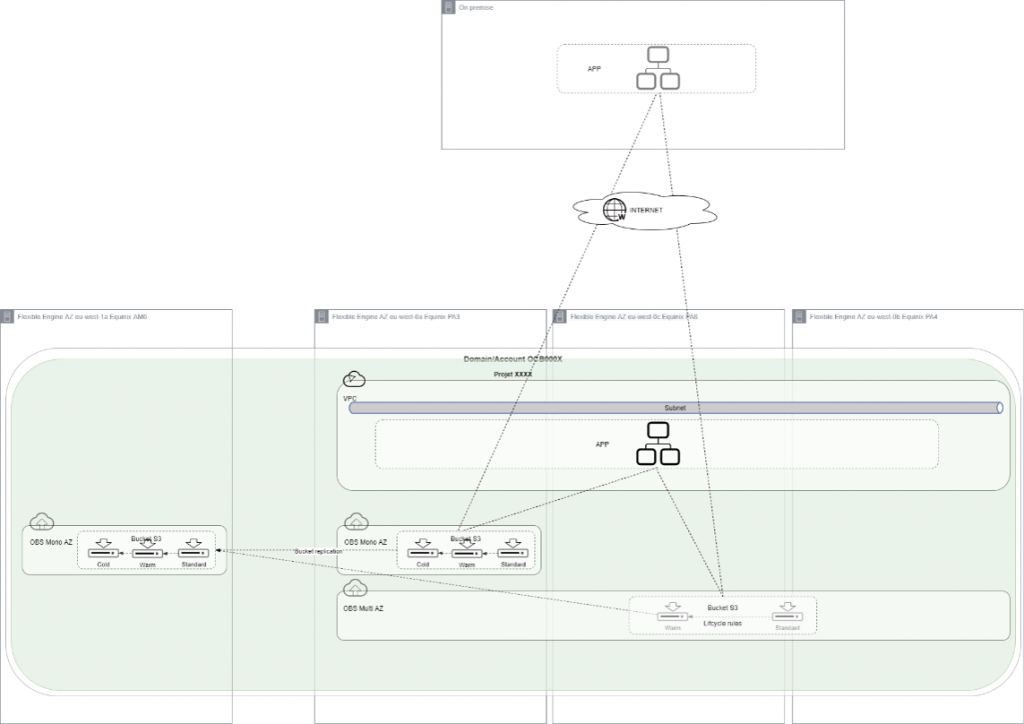
- Use OBS Multi-AZ (exept for cold storage class, which is Mono AZ only)
- Use Life Cycle rules to optimize Class storage
- Implement bucket replication for cross-region replication to Amsterdam
Cloud Native workload
Characteristics
- Massive use of Infra As Code via CI/CD [Terraform provider]
- Data localisation
Solution
- Network services (ELB, NATGW, etc.)
- Managed services CCE, RDS, DDS, etc.
Recommendation
- Respect the best practices of managed services in HA service deployment with Multi-AZ
- Master/Slave cluster services (RDS type): master on eu-west-0b or 0c:
- Services with quorum (CCE type): node distribution on the 3 AZ
- Data backup on Multi-AZ OBS
- Enable CCE autoscaler add-on