Cloud Public Openstack – Flexible Engine
Map Reduce Service (MRS)
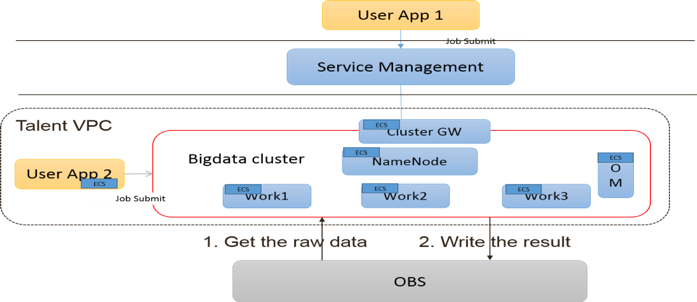
Description

Le service MapReduce (MRS) met à disposition des ressources de stockage et des capacités d’analyse permettant de construire une plateforme de traitement massif de données, et cela de façon fiable, sécurisée et simple d’exploitation.
Les Utilisateurs peuvent ainsi tirer profits des solutions telles que Hadoop, Spark, HBase, ou Hive pour créer rapidement des clusters fournissant des ressources de calcul et de stockage à des fins d’analyse massive de données ou de traitement temps-réel.
Les ressources utilisées pour le calcul et le stockage peuvent être créées et supprimées à la volée en fonction des traitements nécessaires afin d’optimiser les coûts.
Bénéfices
- Simplicité d’utilisation
- Stabilité et fiabilité
- Différents types de stockage : Object Storage Service, Elastic Volume Service, Local Disk
- Amélioration de l’Open Source
Composants
- Analyse et calculs massifs de données
- Hadoop: Basé sur Hadoop afin de déployer une infrastructure distribuée, MRS utilise MapReduce pour effectuer des traitements parallèles sur de gros volumes de données (To et au-delà).
- Spark: Spark est un framework de traitements distribués par lots. Il supporte du développement dans différents langages de programmation tels que Scala, Java et Python. De plus il met à disposition Spark SQL afin de requêter et d’analyser les données via le langage SQL standard.
- HBase: Hadoop Database (HBase) est un système de gestion de base de données non-relationnel distribuée, écrit en Java, disposant d’un stockage structuré pour les grandes tables. Il fournit ainsi une solution fiable, performante et scalable pour compléter les bases de données relationnelles dans le traitement de données massives.
- Hive: Apache Hive est une infrastructure d’entrepôt de donnée intégrée à Hadoop permettant l’analyse, le requétage via un langage proche syntaxiquement de SQL ainsi que la synthèse de données.
- Stockage massif de données
Le système de fichiers distribués Hadoop ou Hadoop distributed file system (HDFS) est un système de fichiers distribué qui donne un accès haute-performance aux données réparties dans des clusters Hadoop. Comme d’autres technologies liées à Hadoop, HDFS est devenu un outil clé pour gérer des pools de Big Data et supporter les applications analytiques. Après avoir été traités et analysées, les données sont cryptées via SSL et stockées dans le stockage objet (OBS) ou dans HDFS.
MRS supporte les types d’ECS suivants.
| Environnement | |
| Standard à finalité générale « s » | s1.xlarge |
| s1.4xlarge | |
| s1.8xlarge | |
| c2.xlarge | |
| c2.2xlarge | |
| Disque optimisé « d » | d1.xlarge |
| d1.2xlarge | |
| d1.4xlarge | |
| d1.8xlarge |
Limitations
Des données sont souvent supprimées des serveurs utilisant d’importants espaces de disques (d1.4xlarge. et d1.8xlarge.). Pour supprimer entièrement les données du serveur, il est nécessaire de formater le disque lors de la désinstallation des clusters. Les limitations suivantes doivent être prises en compte pendant l’utilisation de Map Reduce Service : Si des fichiers sont téléchargés via le Web, la taille du fichier ne peut pas excéder 50 Mo. Si les données sont transférées, la capacité maximale des données est de 5 Go. La largeur de bande maximale du réseau est de 5 Go/s.
Tarification
La tarification du service MRS est fonction de l’usage des serveurs Elastic Cloud sous-jacents et des coûts de licence.