Cloud Public Openstack – Flexible Engine
Cloud Stream Service (CS)
Description
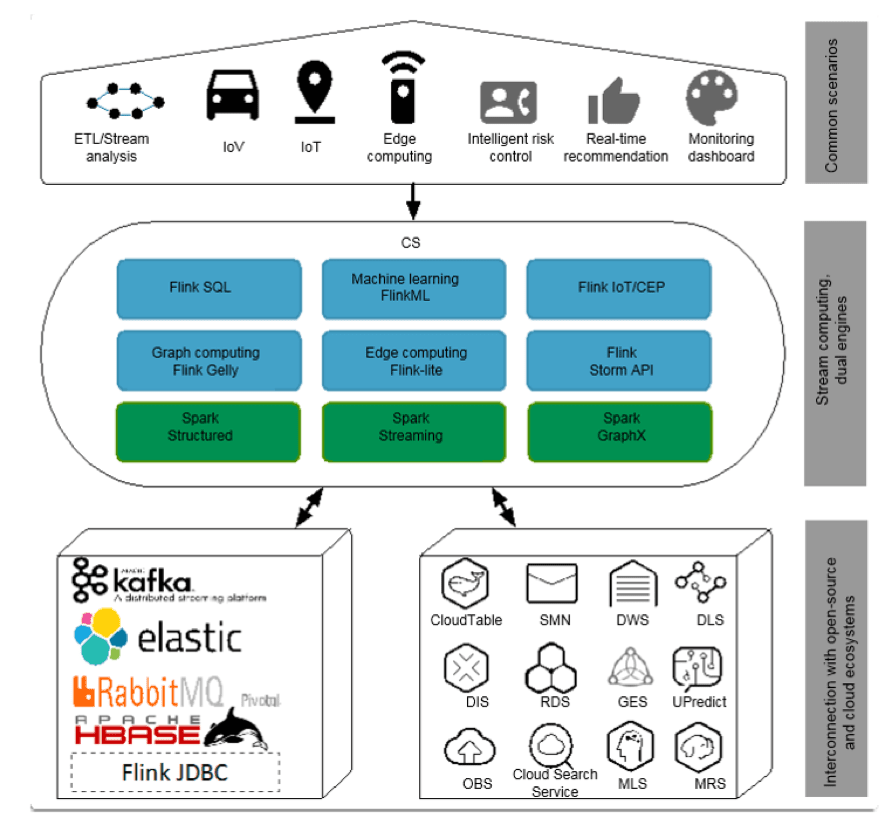
Cloud Stream Service (CS) est un service d’analyse de flux de données massives en temps réel fonctionnant sur le cloud public. Les clusters informatiques sont entièrement gérés par CS, ce qui vous permet de vous concentrer sur les services Stream SQL. CS est entièrement compatible avec les API Apache Flink 1.5.3 et Apache Spark 2.2.1.
Promu dans le domaine des TI, CS offre un calcul distribué en temps réel avec une faible latence (latence de milliseconde), un débit élevé et une grande fiabilité. Alimenté par Flink, CS intègre des fonctionnalités et une sécurité améliorée, et prend en charge le traitement des flux et les méthodes de traitement par lots. Il fournit des fonctionnalités Stream SQL obligatoires pour le traitement des données, et ajoutera des algorithmes d’apprentissage automatique et de calcul graphique à Stream SQL à l’avenir.
Fonctionnalités
- Grandes capacités d’analyses en ligne de flux SQL
Les fonctions d’agrégation, telles que Window et Join, les fonctions géographiques et les fonctions CEP sont prises en charge. SQL est utilisé pour exprimer la logique opérationnelle, facilitant la mise en œuvre des services.
- StreamingML
CS fournit plusieurs méthodes d’apprentissage machine en streaming pour analyser et prédire les données en temps réel. Vous n’avez qu’à appeler les fonctions associées via des instructions SQL pour implémenter les statistiques de données, la détection d’anomalies, le clustering en temps réel et l’analyse de séries temporelles.
- Analyse de la localisation géographique
CS offre des fonctions d’analyse de localisation géographique pour analyser les données géospatiales en temps réel. Vous pouvez effectuer la détection de lacet et la géo-clôture via des instructions SQL.
- CEP SQL
CS fournit le filtrage et la détection basés sur Match Recognize pour aider le personnel de l’entreprise dans la détection d’anomalies basées sur des règles d’événements complexes via SQL. Vous pouvez appliquer cette fonction dans divers scénarios, tels que la détection de fraude, la détection du comportement anormal du véhicule et la détection de l’état de fonctionnement anormal des dispositifs industriels.
- Visualisation des données
CS utilise des graphiques de différents types pour afficher les données de sortie des travaux en temps réel. Vous pouvez directement utiliser API Gateway (APIG) pour accéder aux données de travail et personnaliser les données à visualiser.
- Éditeur Visual SQL
CS fournit un éditeur visuel pour les utilisateurs qui ne sont pas familiarisés avec le développement SQL. L’éditeur visuel encapsule les services en amont et en aval (tels que DIS et CloudTable) et les opérateurs logiques internes (tels que le filtre et la fenêtre) qui doivent être interconnectés avec CS dans des composants glisser-déposer. Il vous permet de créer facilement une topologie de travail en faisant glisser les éléments requis dans le canevas, puis en les connectant. En cliquant sur chaque élément du canevas, vous pouvez définir les paramètres associés.
- Création exclusive de cluster et allocation de quotas de ressources pour les emplois
Les tenants peuvent créer des clusters exclusifs, qui sont physiquement isolés des clusters partagés et des clusters d’autres tenants et ne sont pas soumis à d’autres emplois. Les tenants peuvent également configurer le quota SPU maximal pour leurs clusters exclusifs et allouer des clusters disponibles et un quota SPU à leurs sous-utilisateurs.
- Online SQL job testing
Le débogage des travaux vous aide à vérifier si la logique d’une instruction SQL est correcte. Une fois les exemples de données saisis manuellement ou à l’aide d’OBS, la logique de l’instruction SQL correcte exportera les résultats comme prévu.
Bénéfices
Calcul de flux en temps réel distribué
CS prend en charge les clusters distribués à grande échelle et la mise à l’échelle automatique des clusters. Vous pouvez ajuster la capacité de votre cluster en fonction des ressources requises par vos travaux, ce qui minimise les coûts.
Facile à utiliser
Vous pouvez utiliser l’éditeur SQL en ligne pour compiler les instructions Stream SQL afin de définir le flux source, le flux de données et la logique de traitement des données pour rapidement implémenter la logique métier. Avec CS, vous pouvez analyser les données en streaming sans gérer les clusters et apprendre plus de compétences en programmation.
Support de clusters exclusifs
CS prend en charge la mise à l’échelle automatique et est entièrement géré, ce qui vous libère de la gestion des clusters, des frameworks Big Data et des frameworks de planification des ressources. Il visualise également l’état d’exécution de vos tâches soumises. Vous pouvez exécuter vos tâches dans un cluster partagé ou un cluster exclusif. Les grappes exclusives sont physiquement isolées des grappes partagées et des autres grappes de locataires. Vous pouvez également gérer le quota des grappes exclusives.
Isolement sécurisé
Les mécanismes de protection des tenants assurent la sécurité d’emploi. Les clusters informatiques des tenants sont physiquement isolés les uns des autres et protégés par des configurations de sécurité indépendantes.
Haut débit et faible latence
Le modèle de flux de données d’Apache Flink est utilisé pour obtenir un cadre informatique en temps réel. Les ressources de calcul haute performance sont utilisées pour consommer les données de vos clusters Kafka, DMS Kafka et MRS Kafka créés. Un seul SPU traite environ 10000 messages par seconde.
Pay-as-you-go
Vous êtes seulement chargé pour l’unité de traitement de flux (SPU) ressources que vous utilisez par durée d’utilisation (secondes). Un SPU contient un noyau et 4 Go de mémoire.
Cas d’usage
Analyse de flux en temps réel
IoT