Public Cloud – Flexible Engine
Cloud Stream – analyse your data in real-time
Analyse real-time big data stream analysis service running on the public cloud
Cloud Stream Service is a real-time big data stream analysis service running on the public cloud. Computing clusters are fully managed by Cloud Stream, enabling you to focus on Stream SQL services. Cloud Stream is compatible with Apache Flink APIs, and Cloud Stream jobs run in real time.
Cloud Stream is a distributed real-time stream computing system featuring low latency (millisecond-level latency), high throughput, and high reliability. Powered on Flink and Spark Streaming, Cloud Stream integrates enhanced features and security, and supports both stream processing and batch processing methods. It provides mandatory Stream SQL features for data processing, and will add algorithms of machine learning and graph computing to Stream SQL in the future.
Product architecture
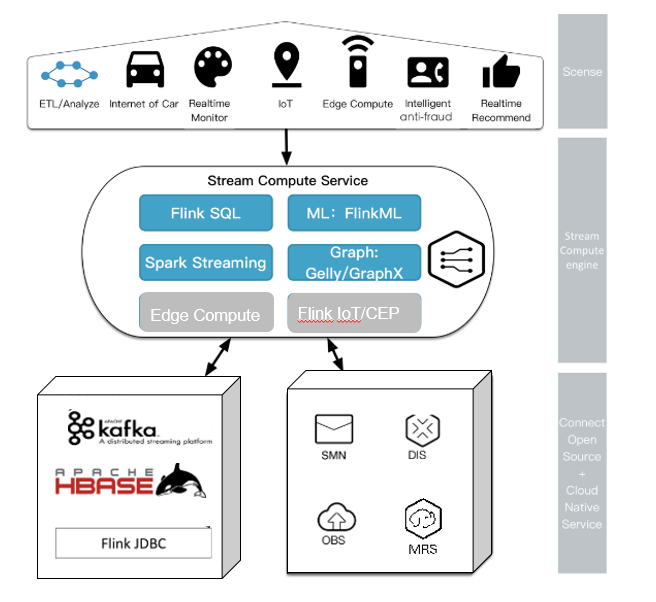
Cloud Stream Service is based on Flink and Spark engine, it support rich real-time analysis capabilities, include Stream SQL, open-source native FlinkML, Gelly and so on. It support two kind of ecological, one is the HUAWEI cloud services, including DIS and SMN. Another is that through exclusive cluster and peering function, it can connect to open-source cluster like Kafka/Hbase.
Cloud Stream support to connect with following source and sink:
Source:
- DIS: Read streaming data from DIS.
- OBS: Read file once from OBS object.
- Kafka: Consume data from Kafka, this feature only support on exclusive cluster, cause Kafka cluster is user’s cluster, it need to create vpc peering between exclusive cluster and user’s Kafka cluster, thus the exclusive cluster can access user’s data. kafka supported version must be above 0.1
Sink:
- DIS: Send streaming data from DIS.
- Kafka: Produce data to Kafka, this feature only support on exclusive cluster, cause Kafka cluster is user’s cluster, it need to create vpc peering between exclusive cluster and user’s Kafka cluster, thus the exclusive cluster can access user’s data.
- SMN: Send message or mail through SMN.
These features are supported in Stream SQL, user can just write sql to connect with these services. In Flink jar or Spark Streaming jar, user can also access these feature through user defined code base on Flink API or Spark API.
Cloud Stream has the following advantages
Easy to Use
You only need to compile Stream SQL statements in the editor to implement business logic.
Fully Managed
Cloud Stream provides visualized information on running jobs.
Pay-as-you-go
Users only need to pay for the SPUs they use. One SPU includes a one-core CPU and 4 GB memory.
Just Use It
You only need to compile Stream SQL statements to submit and run jobs without the need of focusing on big data frameworks such as Hadoop, Flink, and ZooKeeper.
Isolation
Tenants’ exclusive clusters are physically isolated from each other, so that they can submit user defined job on their own cluster.
High throughput and low latency
The Apache Flink Dataflow model is used. The natural pressure mechanism is supported. Real-time data analysis and transfer minimize the data latency.
Cloud Stream provides the following feature
- Stream SQL online analysis
Aggregation functions, such as Window and Join, are supported. SQL is used to express business logic, facilitating service implementation - Distributed real-time computing
Large-scale cluster computing and auto scaling of clusters reduce costs greatly. - Fully hosted clusters
Cloud Stream provides visualized information on running jobs. - Pay-as-you-go
The pricing unit is stream processing unit (SPU), and an SPU contains one core and 4 GB memory. You are charged based on the running duration of specified SPUs, accurate to seconds. - High throughput and low latency
Cloud Stream enables real-time computing services with millisecond-level latency. - Interconnection with SMN
Cloud Stream can connect to Simple Message Notification (SMN), enabling real-time transmission of data analysis results and alarm information to user’s mobile phones in IoT scenarios. - Online SQL job debug
Job debugging helps you check whether the SQL statement logic is correct. After sample data is input manually or using Object Storage Service (OBS) buckets, the correct SQL statement logic will export results as expected. - Spark streaming and structured streaming
You can submit customized spark streaming jobs in exclusive clusters. - Exclusive cluster creation and resource quota allocation for jobs
Tenants can create exclusive clusters, which are physically isolated from shared clusters and other tenants’ clusters and are not subject to other jobs. They can also configure the maximum SPU quota for their exclusive clusters and allocate available clusters and SPU quota for owned users. - Customized Flink job
You can submit customized Flink jobs in exclusive clusters.
Function List
Cloud Stream enables a user to create a real-time analysis job using Stream SQL or User Defined Jar. It also enables a tenant to create exclusive cluster which is physically isolated from the computing resources of other tenants.
| Feature | Description | |
| Stream SQL | Window The window is used to calculate the aggregate value over a period of time or within a certain amount. For example, a website’s 5-minute clickthrough rate
Do aggregation every period of time(or amount).
Do aggregation every records come. Join Geospatial Function ST_DISTANCE/ST_OVERLAPS/ST_INTERSECTS/ST_WITHIN Machine Learning Function |
|
| CEP | CEP API Support the standard Oracle pattern matching grammar – Match Recognize. The ability to recognize patterns found across multiple rows is important for many kinds of work. Examples include all kinds of business processes driven by sequences of events, such as security applications, where unusual behavior must be detected, and financial applications, where you seek patterns of pricing, trading volume, and other behavior. Other common uses are fraud detection applications and sensor data analysis. One term that describes this general area is complex event processing, and pattern matching is a powerful aid to this activity. |
|
| Multi-type Mode | Shared mode |
Serverless and fully managed Stream sql job |
| Exclusive mode |
Isolated Multi-type job Open Source Ecology |
|
| Multi Stream Engine | Flink | Compatible with open source Fink 1.4. |
|
Spark Streaming Spark Structured Streaming |
Compatible with open source Spark 2.2. | |
| Source And Sink | Source:
Sink:
|
|
| Feature | Description | |
| Job Management | Create Stream SQL Job |
|
| Create User Defined Jar Job |
|
|
| Starting job | The user can start created jobs to make it run. | |
| Stopping job | The user can stop running jobs | |
| Deleting job | The user can delete a job with any status. | |
| Monitoring job |
|
|
| Template Management | Create SQL Template | To quickly create stream jobs, Cloud Stream provides the function of customizing job templates. The user can create templates for some Common business. |
| Modify SQL Template | The user can modify created templates. | |
| Delete SQL Template | The user can delete created templates. | |
| Using SQL Template | The user can use created templates when create a new Stream SQL job. | |
| Cluster Management | Create exclusive cluster | The domain user can create exclusive cluster and set the maximum resource that the cluster can use. The exclusive cluster is physically isolated from the computing resources of other tenants. |
| Modify exclusive cluster quota | The domain user can modify the maximum resource that the cluster can use. | |
| Delete exclusive cluster | The domain user can delete created clusters. Once the cluster is deleted, all jobs in the cluster will be deleted also. | |
| Allocate user quota | The domain user can allocate the maximum resources that the sub-user can use. | |
| Allocate user cluster | The domain user can allocate which clusters that the sub-user can use. | |
| Manage tenant jobs | The domain user can start/stop/delete the jobs of his sub-users. | |
Specifications
Anti-DDoS supports traffic cleaning only for the ECThe user can submit job to the cluster created by Cloud Stream, user only know the resource as SPU.
| Parameter | Description |
| SPU | SPU is a minimum calculation unit. An SPU consists of a 1-core CPU and 4 GB memory. |
| Parallelism | Indicates the number of tasks carried on a job. |
Cloud Stream Job Specification:
| Item | Specifications |
| Maximum number of draft jobs | 100 |
| Maximum job name length | 57 Bytes |
| Maximum job desc length | 512 Bytes |
| Maximum sql length | 10000 Bytes |
| Maximum job spu | 400 |
| Maximum job parallelism | 50 |
Cloud Stream Template Specification: Template is some sql samples, user can easy to modify and create new sql job base on it.
| Item | Specifications |
| Maximum template count | 100 |
| Maximum template sql length | 10000 Bytes |
| Maximum template name length | 64 Bytes |
| Maximum template desc length | 512 Bytes |
Tenant exclusive cluster specification:
| Item | Specifications | Description |
| Maximum spu quota of a single cluster | 400 | The maximum quota of a single cluster can use. |
| Maximum domain clusters number | 10 | The maximum number of exclusive clusters user can create |
| Maximum spu quota user can use | 1000 | The maximum spu quota the user can use. E.g. If one user is allocated 3 exclusive cluster, the maximum spu of all these 3 clusters he can use cannot greater than 1000 |
| Maximum cluster name length | 100 Bytes | |
| Maximum cluster desc length | 512 Bytes |
Application Scenarios
Cloud Stream focuses on Internet and Internet of Things (IoT) service scenarios that require timeliness and high throughput. Basically, Cloud Stream provides Internet of Vehicles (IoV) services, online log analysis, online machine learning, online graph computing, and online algorithm application recommendation for multiple industries, such as small- and medium-sized enterprises in the Internet industry, IoT, IoV, and anti-financial fraud.
Real-time stream analysis
Purpose: to analyze big data in real time
Feature: Complex stream analysis methods, such as Window, CEP, and Join, can be performed on stream data with millisecond-level latency.
Application scenarios: real-time log analysis, network traffic monitoring, real-time risk control, real-time data statistics, and real-time data Extract-Transform-Load (ETL)

IoT
Purpose: to analyze online IoT data
Feature: IoT services call the APIs of Cloud Stream. Cloud Stream then reads sensor data in real time and executes users’ analysis logic. Analysis results are sent to services, such as Data Ingestion Service (DIS), for data persistency, alarm or report display, or visual display of results.Application scenarios: elevator IoT, industrial IoT, shared bicycles, IoV, and smart home.
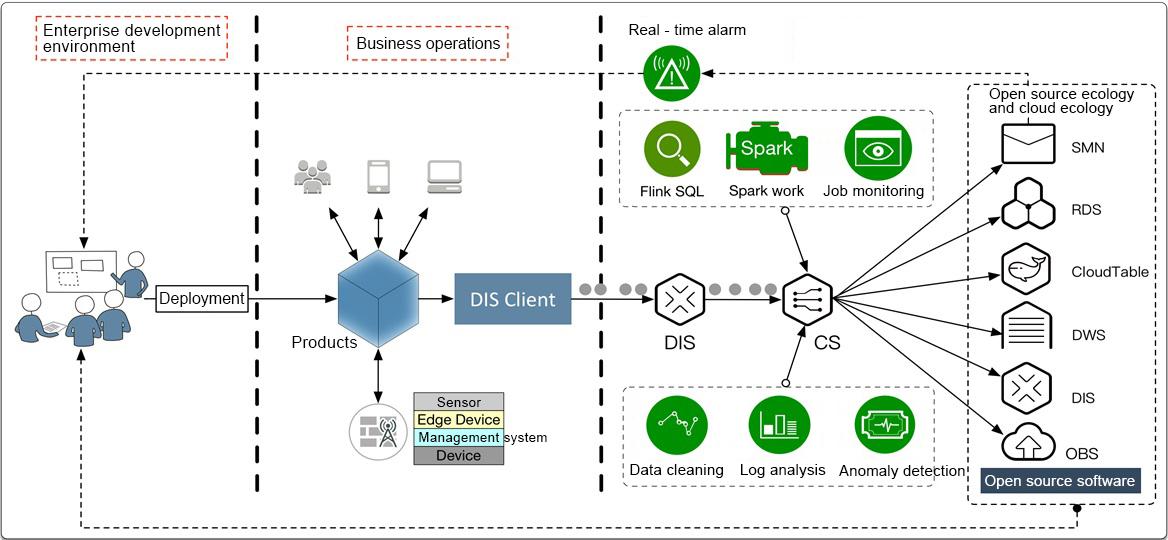
Related Services
Cloud Stream works with the following services :
- DIS
By default, DIS serves as a data source of Cloud Stream and stores outputs of Cloud Stream jobs. For more information about DIS, see Data Ingestion Service User Guide.
- Data source: DIS accesses user data and Cloud Stream reads data from the channel used by DIS as input data for jobs.
- Data output: Cloud Stream writes output of jobs into DIS.
- Object Storage Service (OBS)
OBS serves as a data source and backs up checkpoint data for Cloud Stream. For more information about OBS, see Object Storage Service User Guide.
- Data source: Cloud Stream reads user-stored data from OBS as input data for jobs.
- Checkpoint data backup or job log saving: If the checkpoint function or job log saving function is enabled, Cloud Stream stores job snapshots or logs to OBS. In the event of exceptions, Cloud Stream can recover the job based on checkpoint data backup or queries job logs to locate the fault.
- Identity and Access Management (IAM)
IAM authenticates access to Cloud Stream. For more information about IAM, see the Identity and Access Management User Guide.
- Cloud Trace Service (CTS)
CTS provides users with records of operations on Cloud Stream resources, facilitating query, audit, and backtracking. For more information about CTS, see the Cloud Trace Service User Guide.
- Elastic Cloud Server (ECS)
ECS provides Cloud Stream with a computing server that consists of CPUs, memory, images, and Elastic Volume Service (EVS) disks and allows on-demand allocation and elastic scaling. For more information about ECS, see the Elastic Cloud Server User Guide.
- Simple Message Notification (SMN)
SMN provides reliable and flexible large-scale message notification services to Cloud Stream. It significantly simplifies system coupling and pushes messages to subscription endpoints based on requirements. For more information about SMN, see the Simple Message Notification User Guide.
Usage Restrictions
Cloud Stream Job Specification:
| Item | Specifications |
| Maximum number of draft jobs | 100 |
| Maximum job name length | 57 Bytes |
| Maximum job desc length | 512 Bytes |
| Maximum sql length | 10000 Bytes |
| Maximum job spu | 400 |
| Maximum job parallelism | 50 |
Cloud Stream Template Specification: Template is some sql samples, user can easy to modify and create new sql job base on it.
| Item | Specifications |
| Maximum template count | 100 |
| Maximum template sql length | 10000 Bytes |
| Maximum template name length | 64 Bytes |
| Maximum template desc length | 512 Bytes |
Tenant exclusive cluster specification:
| Item | Specifications | Description |
| Maximum spu quota of a single | 400 | The maximum quota of a single |
| cluster | cluster can use. | |
| Maximum domain clusters number | 10 | The maximum number of exclusive clusters user can create |
| Maximum spu quota user can use | 1000 | The maximum spu quota the user can use. E.g. If one user is allocated 3 exclusive cluster, the maximum spu of all these 3 clusters he can use cannot greater than 1000. |
| Maximum cluster name length | 100 Bytes | |
| Maximum cluster desc length | 512 Bytes |
Version restriction
| Item | Version |
| Flink | 1.4 |
| Kafka | above 0.1 |
| HBase | 1.3.1 |
| Spark | 2.2 |