Public Cloud – Flexible Engine
Map Reduce Service – launch your Hadoop and Kafka clusters in just a few minutes
Big Data solution that provides storage resources and analysis capabilities to build a massive data processing platform

With the rapid development of the Internet era, enterprise data is increasing explosively. There is urgent demand developing to find ways to generate value from the complex and chaotic data and to use this data to innovate and seize business opportunities. Obviously, conventional data processing is not able to deliver in the world of big data.
MapReduce Service (MRS) is a big data service on public cloud, accurately to say, it is “Hadoop as a service”. MapReduce Service does not mean only having MapReduce, but also other components from Hadoop family. Using the name “MapReduce” is just because MapReduce is the most representative component in Hadoop family and it is the foundation of Hadoop distributed computing frame.
The MRS provides storage and analytic capabilities for massive data and builds a reliable, secure, and easy-to-use operation and maintenance (O&M) platform.
- Users can quickly create an analysis cluster that includes Hadoop, Spark, HBase, and Hive to provide storage and analysis capabilities for massive sets of data.
- Users can also quickly create a streaming cluster that includes Storm and Kafka to provide a real-time distributed computing framework and analyze and compute data streams.
After data storage and computing are completed, the cluster can be terminated, and no further charges will be incurred. Clusters may also be run permanently.
Benefits
Anti-DDoS service support
Ease-of-use
- A highly available commercial Hadoop big data platform can be built by performing a few steps within minutes.
- MRS provides a user-friendly web-based console, enabling you to perform management operations with ease.
- Stability and reliability
- 99.9% service availability: Critical services of MRS, such as NameNode and HMaster, are working in active-standby mode. In the event of an active server failure, services are automatically switched over to the standby server within minutes.
MRS supports multiple storage types:
- OBS
Encrypted transmission: Data is transmitted to OBS using SSL and table-level encryption is supported, ensuring data security. - Elastic Volume Service (EVS)
For the preceding storage types, data is stored in three copies. Additionally, Hadoop employs the three copies mechanism. For this reason, user data is stored in nine copies (3 x 3), remarkably improving data reliability.
- Local storage (Only d1.4xlarge and d1.8xlarge ECS instance support.)
Open source enhancement
In addition to capabilities consistent with the Hadoop open source community, MRS enhances some capabilities, including:
Spark:
- Works compatible with most Hive syntax, providing seamless switchovers for Hive user.
- Works compatibly with standard SQL syntax, simplifying migration of users’ services based on traditional relational databases.
- Optimizes data skew and makes full use of CPUs, improving performance.
- Optimizes and merges small files, improving performance.
Hive:
- Supports column encryption, improving security of users’ sensitive data such as salary data.
- Supports HBase deletion, enabling tenants to delete a single piece of data stored on HBase and simplifying operations.
- Supports row delimiters, compatible with more user data types.
- Supports CSV, making it more convenient to use together with Windows Office and other conventional databases.
- Flexible data storage format, support JSON, CSV, TEXTFILE, RCFILE, ORCFILE, SEQUENCEFILE etc., and supports custom extensions.
HBase:
- Supports secondary indexes, helping tenants quickly locate data to be read.
Scenarios
MRS builds a reliable, secure, and easy-to-use O&M platform and provides storage and analysis capabilities for massive data, helping address enterprise data storage and processing demands. It enables you to quickly build a Hadoop, Hive, or Spark cluster to analyze massive data, build an HBase cluster for querying massive data in milliseconds, build a Kafka, Storm cluster to process data streams of a massive scale on a real-time basis. MRS supports the following scenarios:
- Analysis and computing of massive data: log analysis, Click stream analysis, Genomics, and recommender systems.
User can import the data to be analyzed from OBS or HDFS and submit an analysis job. The following job types are supported:
MapReduce job: Hadoop is supported. MapReduce is used to implement parallel computing of large data sets.
Spark/Spark SQL job: Spark is supported. Spark provides analysis and mining and iterative memory computing capabilities. Additionally, Spark SQL enables data to be queried and analyzed using SQL statements.
HQL job: Hive is supported. Hive is a data warehouse framework built on Hadoop. It provides storage of structured data using the HQL, a language like the SQL. Hive converts HQL statements to MapReduce or Spark tasks for querying and analyzing massive data stored in clusters.
- Processing of massive data in a quasi-real-time manner: risk management, CDR query and so on.
HBase: HBase is a column-based distributed storage system that features high reliability, performance, and scalability. It is designed to eliminate the limitations of relational databases in processing massive data, and ensure quasi real-time data access to large tables.
In the scenario described above, there are two ways to access the cluster: One is used the native interface, the user application could access the cluster by native interface when the application is deployed in the same subnet with the cluster; The other is user the MRS console, the user could Submit job and management the file on HDFS.
- Provides a real-time distributed computing framework, analysis and computing massive data streams such as click streams and IoT data streams in a real-time manner.
User can write data streams to message queues such as Kafka. Storm can obtain real-time messages from Kafka, perform high-throughput and low-latency real-time computing, analyzing, querying, and collecting on a real-time platform, and export processed results to HDFS, OBS, or other databases, or directly push the result data to the user interface.
Description
Figure 18: Product Architectureservices.
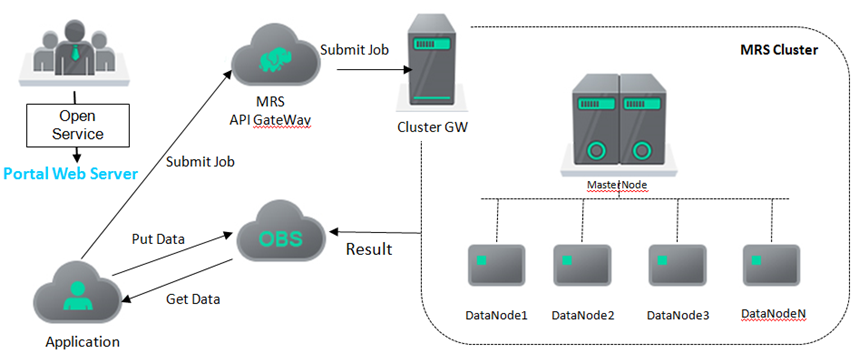
MRS is a web-based service that follows typical architecture of web services. The user interacts with a web console, which provides all the features of MRS. The console interact with the management system to invoke functions. In the management system, there are core management components that provide basic features, operation components, and authentication/authorization components. The management system also interacts with other public cloud services to request resources.
MRS delivers the following functions:
- Analysis and computing of massive data
- Hadoop 2.7.2: Based on Hadoop applying a distributed system infrastructure, MRS uses MapReduce to implement parallel computing of large data sets (TB-level or above).
- Spark 1.5.1: Spark is a distributed batch processing framework. It provides analysis and mining and iterative memory computing capabilities and supports application development in multiple programming languages, including Scala, Java, and Python. Additionally, it provides Spark SQL, which enables data to be queried and analyzed using structured query language (SQL) statements.
- HBase 1.0.2: Hadoop Database (HBase) is a column-based distributed storage system that features high reliability, performance, and scalability. HBase is designed to supplement relational databases in processing massive data.
- Hive 1.3.0: Hive is a data warehouse framework built on Hadoop. It stores structured data using the Hive query language (HQL), a language like the SQL. Hive converts HQL statements to MapReduce or HDFS tasks for querying and analyzing massive data stored in Hadoop clusters.
- Storage of massive data
- Hadoop Distributed File System (HDFS) features high fault tolerance and provides high-throughput data access, applicable to the processing of large data sets. After being processed and analyzed, data is encrypted by using Secure Sockets Layer (SSL) and transmitted to the Object Storage Service (OBS) system or HDFS.
MRS provides users with its features as services. There are two main types of features available to users now: Cluster Management and Jobs Management. Currently we support 8 big data components: Hadoop, Spark, HBase, Hive, Hue, CarbonData, Kafka and Storm.
Characteristics
Cluster Management
MRS provides processing, analysis, and computing capabilities for massive data. It provides a web user interface (WebUI) for you to perform the following operations:
- Creating a cluster:
With easy operations, MRS allows you to create a cluster via console or REST API. Currently there are two types of clusters that are available: One is with Kerberos authentication, the other is not Kerberos authentication. The Kerberos is a third-party authentication and authorization component for BigData components. Clusters can be applied in the following scenarios:
Transient cluster with data stored in OBS: Data storage and computing are performed separately when computing is infrequent. Cluster storage costs are low, and storage capacity is not limited. The data can be deleted at any time from OBS. IO performance is limited by OBS access performance and is lower than HDFS.
Long-Running cluster with data stored in HDFS: Data storage and computing are performed centrally when computing is frequent. Cluster storage costs are high, and storage capacity is limited. The computing performance is high. Data must be exported and stored before the clusters are deleted.
- Managing clusters:
You can manage clusters and terminate a cluster after data processing and analysis are completed.
Monitoring components: A secure and reliable environment is the basis for cluster operating. Additionally, involved components must run properly and all required resources must be provided. MRS monitors and manages the functions of each module in HDFS, providing a secure and reliable operating environment.
Handling alarms: In case of cluster operating exceptions or system faults, MRS will collect fault information and report the information to the network management system for maintenance personnel to locate faults.
Managing configurations: Default configurations are adopted when a cluster is created. Configurations of a cluster can be modified and the modification will take effect after the cluster is restarted.
Querying logs: Operation information about clusters, jobs, and configurations is recorded, helping locate faults in case of cluster operating exceptions.
Managing files: MRS allows data to be imported to HDFS from OBS and exported from HDFS to OBS after analysis and processing. You can also store data in HDFS.
Job Management
- Creating jobs:
A job is an executable program provided by MRS for processing and analyzing user data. MRS supports MapReduce and Spark jobs (Java and Scala Jar, Spark SQL script and Hive SQL script) and allows you to submit Spark SQL statements online to query and analyze data. When the MapReduce and Spark job depends on an additional Jar, the user can load the additional Jar from OBS to HDFS.
- Managing jobs:
You can manage all jobs, view detailed configurations of a job, and delete a job. Note: Job Management do not support in Kerberos cluster.
Hadoop
MRS deploys and hosts Apache Hadoop clusters in the cloud to provide services featuring high availability and enhanced reliability for big data processing and analysis. Hadoop is a distributed system architecture that consists of HDFS, MapReduce, and Yarn. The following describes the functions of each component:
- HDFS
HDFS provides high-throughput data access and is applicable to the processing of large data sets. MRS cluster data is stored in HDFS.
- MapReduce
MapReduce is a programming model that simplifies parallel computing. It gets its name from two key operations: Map and Reduce. Map divides one task into multiple parallel tasks, and Reduce summarizes the processing results of those tasks and produces the final analysis result. MRS clusters allow users to submit self-developed MapReduce programs, execute the programs, and obtain the results.
- Yarn
Yarn is the resource management system of Hadoop. It manages and schedules resources for applications.
Spar SQL
Spark SQL is an important component of Apache Spark and subsumes Shark. It helps engineers who understand conventional databases but do not know MapReduce to quickly get started. Users can directly enter SQLs to analyze, process, and query data.
Spark SQL has the following highlights:
- Works compatible with most Hive syntax, enabling seamless switchover.
- Works compatibly with standard SQL syntax.
- Resolves data skew problems: Spark SQL can join and convert skew data. It evenly distributes data that does not contain skewed keys to different tasks for processing. For data that contains skewed keys, Spark SQL broadcasts the smaller amount of data and uses Map-Side Join to evenly distribute the data to different tasks for processing, fully utilizing CPU resources and improving performance accordingly.
- Optimizes small files: Spark SQL employs the coalesce operator to process small files and combines partitions generated by small files in tables, reducing the number of hush buckets during shuffle and improving performance accordingly.
Hive QL
Hive is a data warehouse framework built on Hadoop. It provides storage of structured data using the Hive query language (HQL), a language like the SQL. Hive converts HQL statements to MapReduce or HDFS tasks for querying and analyzing massive data stored in Hadoop clusters. The console provides the interface for entering Hive SQL commands and supports online HQL statement submission.
- Column Encryption
Hive supports encryption of one or more columns. Columns to be encrypted and the encryption algorithm can be specified when a Hive table is created. When data is inserted into the table using the insert statement, the related columns are encrypted.
The Hive column encryption mechanism supports two encryption algorithms, which can be selected to meet site requirements during table creation: AES (the encryption class is org.apache.hadoop.hive.serde2.AESRewriter).
- Row Delimiter
In most cases, a carriage return character is used as the row delimiter in Hive tables stored in text files, that is, the carriage return character is used as the terminator of a row during search.
However, some data files are delimited by special characters other than a carriage return character.
MRS Hive allows you to use different characters or character combinations to delimit rows of Hive text data. When creating a table, set inputformat to SpecifiedDelimiterInputFormat, and set the following parameter before search each time. Then the table data is queried by the specified delimiter.
set hive.textinput.record.delimiter=’|’;
When you set this parameter, the table data is split by ‘|’.
The further detail information can be found in User Guide of MRS.
- CSV SerDe
Comma separated value (CSV) is a common text file format. CSV stores table data (digits and texts) in texts and uses a comma (,) as the text delimiter.
CSV files are universal. Many applications allow users to view and edit CSV files. CSV files can be used in Windows Office or conventional databases.
MRS Hive supports CSV files. You can import user CSV files to Hive tables or export user Hive table data as CSV files to use them in other applications.
HBase
HBase is a column-oriented distributed cloud storage system that features enhanced reliability, excellent performance, and elastic scalability. It applies to the storage of massive data and distributed computing. You can use HBase to build a storage system capable of storing TB- or even PB-level data. With HBase, you can filter and analyze data with ease and get responses in milliseconds, rapidly mining data value.
HBase applies to the following scenarios:
- Massive data storage
HBase applies to TB- or even PB-level data storage and provides dynamic scaling capabilities so that users can adjust cluster resources to meet specific performance or capacity requirements.
- Real-time query
The columnar and key-value storage models apply to the ad-hoc query of enterprise user details. The master key–based low-latency point query reduces the response latency to seconds or even milliseconds, facilitating real-time data analysis.
HBase has the following highlights:
- The HBase secondary index enables HBase to query data based on specific column values. HBase can quickly locate the data that needs to be read, improving data obtaining efficiency.
Kerberos
MRS uses KrbServer to provide the Kerberos authentication function for all components, thereby implementing reliable authentication mechanisms. User can choose whether support Kerberos when creating cluster. When user enabled the Kerberos authentication, all MRS components need to be authenticated. For more details about Kerberos, visit https://web.mit.edu/kerberos//.
Hue
Hue provides a graphical web user interface (WebUI) for MRS applications. Hue supports components including Hadoop distributed file system (HDFS), Hive, YARN/MapReduce and Spark. On the WebUI provided by Hue, you can perform the following operations on the components:
- HDFS: View files or directories, create files or directories, manage files or directories, delete files or directories, upload files, manually configure HDFS directory storage policies, and configure dynamic storage policies.
- Hive: Edit and execute Hibernate Query Language (HQL) statements, and add, delete, modify, and query databases, tables, and views using MetaStore.
- MapReduce: View the MapReduce tasks that are being executed and complete in the cluster, including viewing their status, start time and end time, and run logs.
- Spark: Edits and executes Spark SQL statements and views the execution result.
CarbonData
Attaches to spark as a data source and provides the functionality of storage and retrieval data for fast query and analysis. CarbonData leverages the distributed processing power of spark to speed up the queries by an order of magnitude faster over PetaBytes of data.
- Supports custom storage format which is highly indexed and compressed there by giving faster query response for ad-hoc and detailed scan queries.
- Unlike HBase which is suitable for filter queries, CarbonData can show increased performance in OLAP and full big scan queries.
- Has very low latency and Point queries are served in milliseconds and big full scan queries in seconds.
- Supports importing of CSV files into CarbonData format.
- Supports creating secondary index on columns thereby improving the efficiency of data retrieval.
Kafka
Kafka is a distributed, partitioned, replicated message publishing and subscription system. It provides features similar to the Java Message Service (JMS), but the design is different. Kafka provides features, such as message persistence, high throughput, multi-client support, and real-time processing, and applies to online and offline message consumption. It is ideal for Internet service data collection scenarios, such as conventional data collection, website active tracing, data monitoring, and log collection.
- Reliability
Message processing methods such as At-Least Once, At-Most Once, and Exactly Once are provided. The message processing status is maintained by Consumers. Kafka needs to work with the application layer to implement the Exactly Once message processing method.
- High Throughput
High throughput is provided for message publishing and subscription.
- Persistence
Messages are stored on disks in persistence mode and can be used for batch consumption and real-time application programs. Data persistence and replication prevent data loss.
- Distribution
A distributed system is easy to be expanded externally. All Producers, Brokers, and Consumers support the deployment of multiple distributed clusters. Systems can be expanded without stopping the running of software or shutting down the machines.
Storm
Storm is a distributed, reliable, and fault-tolerant real-time computing system. It is used to process data streams of a massive scale on a real-time basis. Storm applies to real-time analysis, continuous computation, and distributed Extract, Transform, and Load (ETL). Storm has the following features:
- Distributed Real-time Computing Framework
In a Storm cluster, each machine supports the running of multiple work processes and each work process can create multiple threads. Each thread can execute multiple tasks. A task indicates concurrent data processing.
- High Fault Tolerance
During message processing, if a node or a process is faulty, the message processing unit can be redeployed.
- Reliable Messages
Data processing methods including At-Least Once, At-Most Once, and Exactly Once are supported.
- Security Mechanism
Storm provides Kerberos-based authentication and pluggable authorization mechanisms, supports SSL Storm UI and Log Viewer UI, and supports security integration with other big data platform components (such as ZooKeeper and HDFS).
- Flexible Topology Definition and Deployment
The Flux framework is used to define and deploy service topologies. If the service DAG is changed, users only need to modify YAML domain-specific language (DSL), but do not need to recompile and package service code.
- Integration with External Components
Streaming supports integration with multiple external components such as Kafka, HDFS, HBase, Redis, and JDBC/RDBMS, implementing services that involve multiple data sources.
Multi-Tenant Management
- Definition
An MRS cluster provides various resources and services for multiple organizations, departments, or applications to share. The cluster provides tenants as a logical entity to use these resources and services. A mode involving different tenants is called multi-tenant mode. Currently, tenants are supported by analysis clusters only.
- Principles
The MRS cluster provides the multi-tenant function. It supports a layered tenant model and allows dynamic adding or deleting of tenants to isolate resources. It dynamically manages and configures tenants’ computing and storage resources.
The computing resources indicate tenants’ Yarn task queue resources. The task queue quota can be modified, and the task queue usage status and statistics can be viewed.
Storage resources support HDFS storage. Tenants’ HDFS storage directories can be added or deleted, and the quotas for file quantity and storage space of the directories can be configured.
As the unified tenant management platform of the MRS cluster, MRS Manager provides a mature multi-tenant management model for enterprises, implementing centralized tenant and service management. Users can create and manage tenants in the cluster.
Roles, computing resources, and storage resources are automatically created when tenants are created. By default, all rights on the new computing and storage resources are assigned to the tenant roles.
By default, the permission to view tenant resources, create sub-tenants, and manage sub-tenant resources is assigned to the tenant roles.
After tenants’ computing or storage resources are modified, the related role rights are updated automatically.
MRS Manager supports a maximum of 512 tenants. The tenants that are created by default in the system contain default. Tenants that are in the topmost layer with the default tenant are called level-1 tenants.
- Resource Pool
Yarn task queues support only the label-based scheduling policy. This policy enables Yarn task queues to associate with NodeManagers that have specific node labels. In this way, Yarn tasks run on specified nodes for scheduling and certain hardware resources are utilized. For example, Yarn tasks requiring a large memory capacity can run on nodes with a large memory capacity by means of label association, preventing poor service performance.
On the MRS cluster, users can logically divide Yarn cluster nodes to combine multiple NodeManagers into a resource pool. Yarn task queues can be associated with specified resource pools by configuring queue capacity policies, ensuring efficient and independent resource utilization in the resource pools.
MRS Manager supports a maximum of 50 resource pools. The system has a Default resource pool.
Flavor characteristics:
MRS consists of two types of nodes, the core node and the master node.
MRS core node supports up to nine ECS specifications. Functions will be added in later versions to support more ECS types.
One core node supports one EVS disk up to 32000GB.
The MRS core node supports two types of ECS: ECS with EVS and ECS with local disks. MRS can work well with all the ECS above. The main difference between using these two types of ECS is performance. ECS with local disk provides optimal performance. It is recommended for scenarios that require short analysis time or use HBase.
MRS master node supports up to three ECS specifications. Functions will be added in later versions to support more ECS types.
One master node supports one 400GB EVS disk.
Function characteristics:
MRS supports the following components and Version:
| MRS Components | Version |
| Hadoop | 2.7.2 |
| Spark | 1.5.1 |
| HBase | 1.0.2 |
| Hive | 1.3.0 |
| Kerberos | 1.11.7 |
| Hue | 3.9.0 |
| CarbonData | 1.0.0 |
| Kafka | 0.10.0.0 |
| Storm | 1.0.2 |